

Les projets de "moteurs de recherche sémantiques", ou de "d'accès…

Vocabulaires dans le web de données : quels outils open-source ?
Je travaille régulièrement sur des projets de gestion et/ou de mise en ligne de vocabulaires (thesaurus, taxonomies) en SKOS : pour l’UNESCO – voir le précédent billet -, l’INED (thesaurus Popin), le Luxembourg, l’IRSTEA ou le Réseau Canopé (vocabulaire ScolomFr). Ces projets sont réalisés en utilisant de l’open-source sur toute la chaîne, depuis le back-office de gestion jusqu’à la diffusion conforme aux standards du web de données, en passant par l’alignement ou la conversion depuis des tableaux Excel.
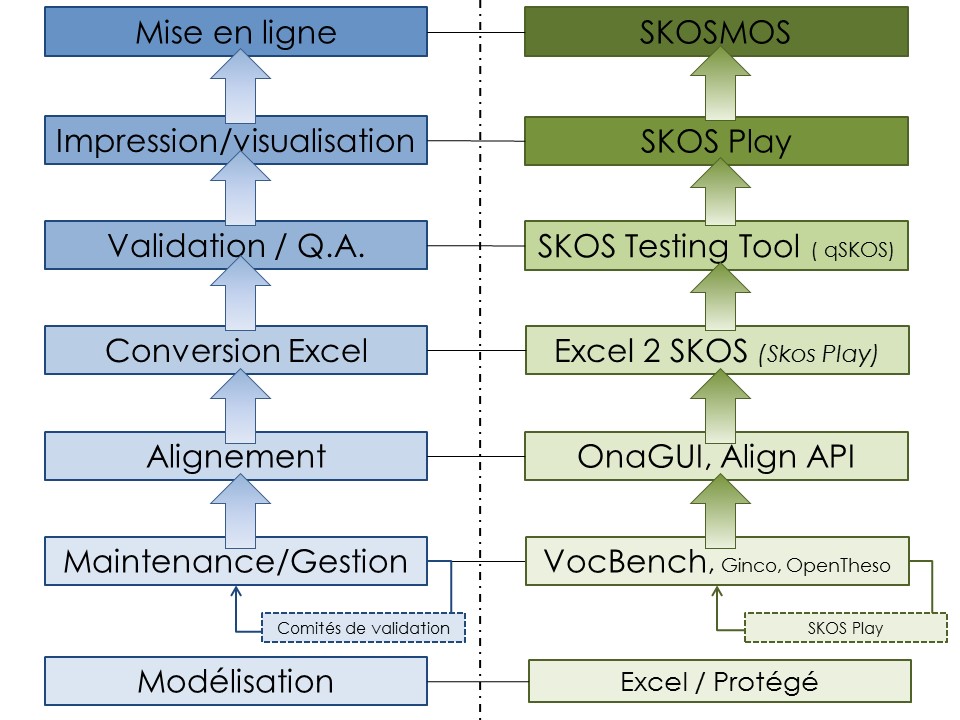
Je vous propose un petit tour d’horizon des outils open-source pour la gestion et la diffusion de vocabulaires contrôlés.
Outils de gestion
Vocbench3
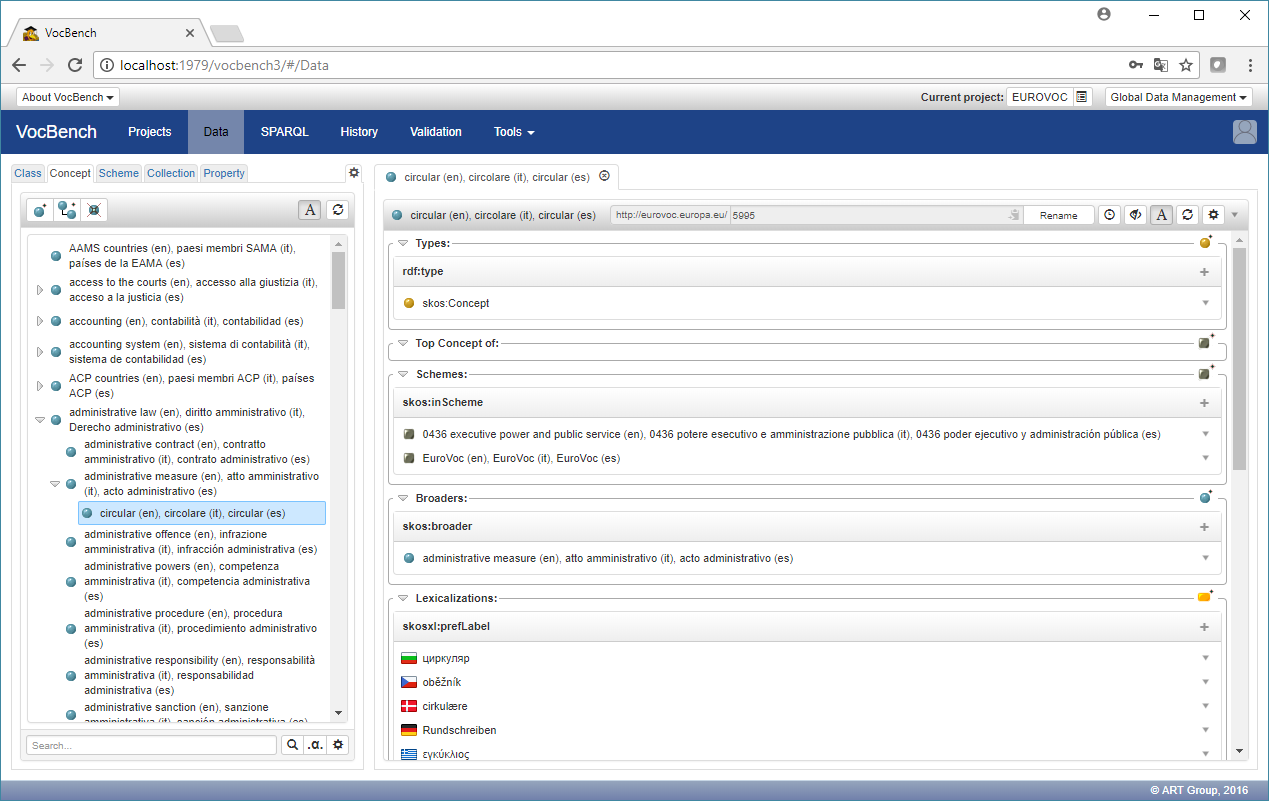
Vocbench3 est l’outil de gestion de référentiels SKOS que je recommande. Il est développé par l’Université de Rome Tor-Vergata, et financé pour 1 ou 2 année encore par le programme de financement européen ISA, ce qui lui donne une bonne visibilité à moyen terme. La communauté d’utilisateurs est large avec beaucoup d’organismes internationaux (FAO/Agrovoc, INRA, Office des Publications de l’UE/Eurovoc, etc.). Le support est bon, l’équipe de développement répond rapidement aux questions.
Coté technique, il est directement basé sur des données RDF, ce qui facilite son intégration dans des environnements techniques basés sur le web de données. Le modèle de données est extensible et permet de gérer des propriétés « customisées » sur les concepts. Vocbench permet également d’éditer des ontologies OWL, sans arriver à concurrencer Protégé.
Ginco
Ginco est l’outil de gestion de vocabulaires développé par le Ministère de la Culture pour la maintenance de ses référentiels. Il a été dès le départ spécifié pour être compatible avec la norme ISO-25964 sur la modélisation des thesaurus, et avec SKOS. Donc en particulier la gestion des facettes, des tableaux de concepts, etc. Il a un pendant « Ginco diffusion » qui motorise le site de diffusion des vocabulaires du MCC.
OpenTheso
OpenTheso est l’outil de gestion SKOS made in CNRS. La communauté d’utilisateurs est dans le monde de la recherche française/francophone (notamment le réseau FRANTIQ).
On pourra consulter la présentation d’OpenTheso à semweb.pro 2017 par Miled Rousset.
Outils de Publication et Visualisation de vocabulaires
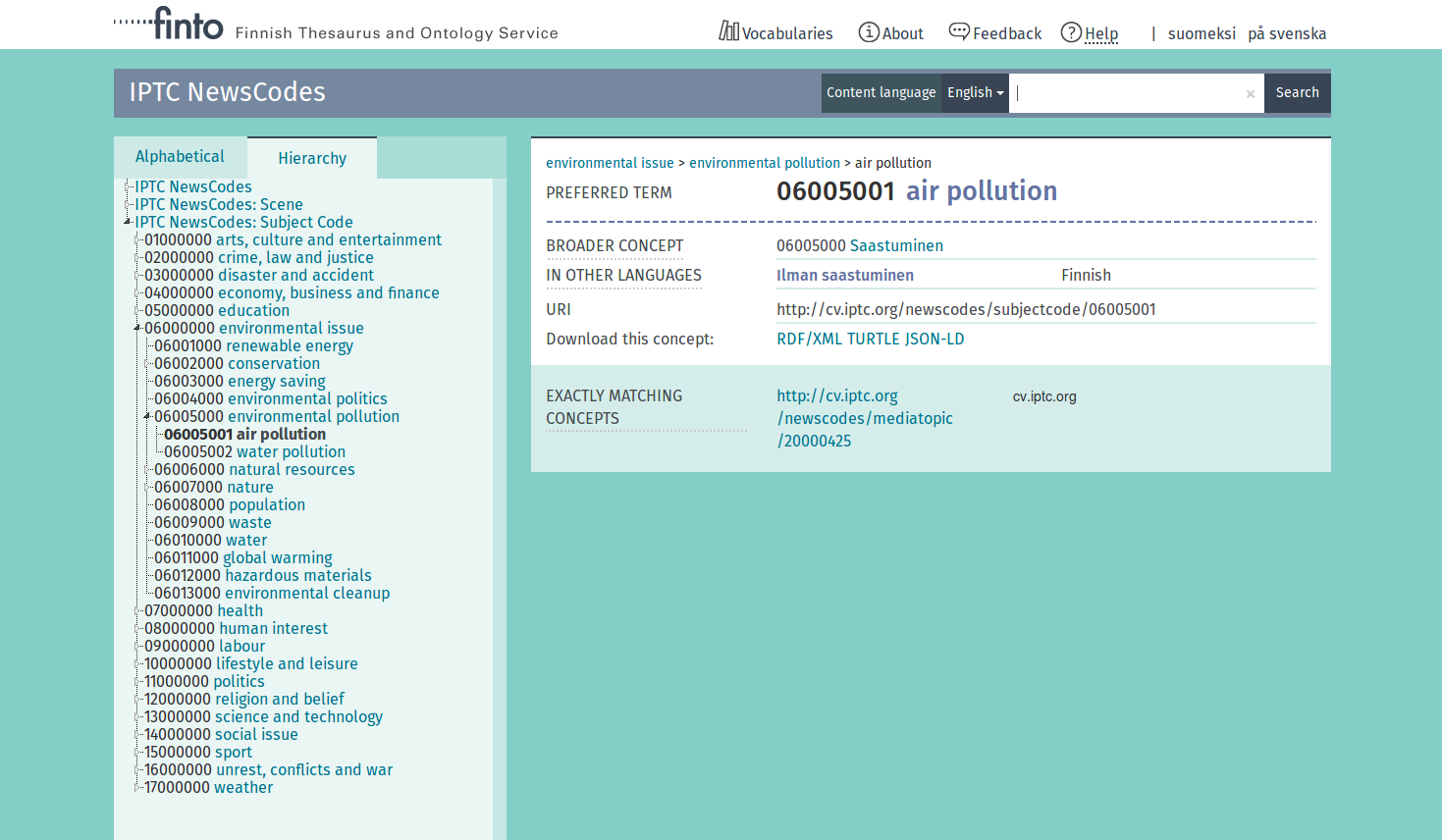
Skosmos
Vous voulez valoriser vos vocabulaires/thesaurus/taxonomies ? Vous avez besoin des les rendre visibles, navigables, interrogeables par les utilisateurs ? Vous voulez recevoir du feedback, faire participer une communauté ? Skosmos est l’outil de choix.
Développé par la Bibliothèque Nationale de Finlande pour son portail « finto.fi » (parlez-vous finnois ?), Skosmos propose une interface de rendu très propre avec toutes les fonctions de navigation dans des vocabulaires contrôlés : listes alphabétiques, arborescence hiérarchique, recherche plain-texte avec autocompletion, gestion des groupes/collections SKOS, affichage propre des alignements avec d’autres vocabulaires. Il s’adapte assez facilement pour le mettre aux couleurs de l’institution. Il prend en charge la négociation de contenu pour l’accès aux données brutes en RDF. L’interface inclut également un formulaire permettant d’envoyer du feedback à l’équipe de maintenance du thesaurus.
L’équipe de développement répond très vite aux questions, le code PHP est de qualité, l’outil est vivant et de nouvelles versions sont disponibles régulièrement.
Skosmos est à mon sens LE meilleur outil pour la diffusion de vocabulaires en SKOS.
Skos Play
SKOS Play est l’outil que je développe depuis 2013 pour faire de la publication et de la visualisation de référentiels SKOS. Il permet de générer des documents PDF des vocabulaires, des sorties HTML dynamiques (arbres dépliables),des listings alphabétiques, des tableaux de traduction ou d’alignement, ou des data visualisations. A titre d’exemple on pourra consulter les rendus du code Rome de Pôle Emploi en SKOS.
SKOS Play est intégré dans la plateforme de publication des vocabulaires du MCC, et dans celle de l’UNESCO, pour la génération des PDFs. Le service en ligne est quant à lui utilisé plus de 500 fois par mois.
Conversion Excel, contrôle qualité, alignement
Skos Play convert
SKOS Play inclut un service de génération de données RDF/SKOS depuis des tableaux Excel (voir précédent billet).
Soyons honnêtes : rien ne remplace Excel  ! pour de la saisie ou de l’analyse de données en masse, avoir une vue globale sur ces données, faire des reporting, gérer facilement plusieurs vocabulaires… Pas de courbe d’apprentissage, pas d’outil à installer, grande efficacité de saisie. Et si on utilise un environnement en ligne type Google Sheets, on gagne l’aspect collaboratif.
! pour de la saisie ou de l’analyse de données en masse, avoir une vue globale sur ces données, faire des reporting, gérer facilement plusieurs vocabulaires… Pas de courbe d’apprentissage, pas d’outil à installer, grande efficacité de saisie. Et si on utilise un environnement en ligne type Google Sheets, on gagne l’aspect collaboratif.
Cette passerelle Excel-RDF-SKOS s’est révélée très importante pour faire les reprises ou les créations initiales de vocabulaires, avant de les basculer dans des outils de gestion comme VocBench.
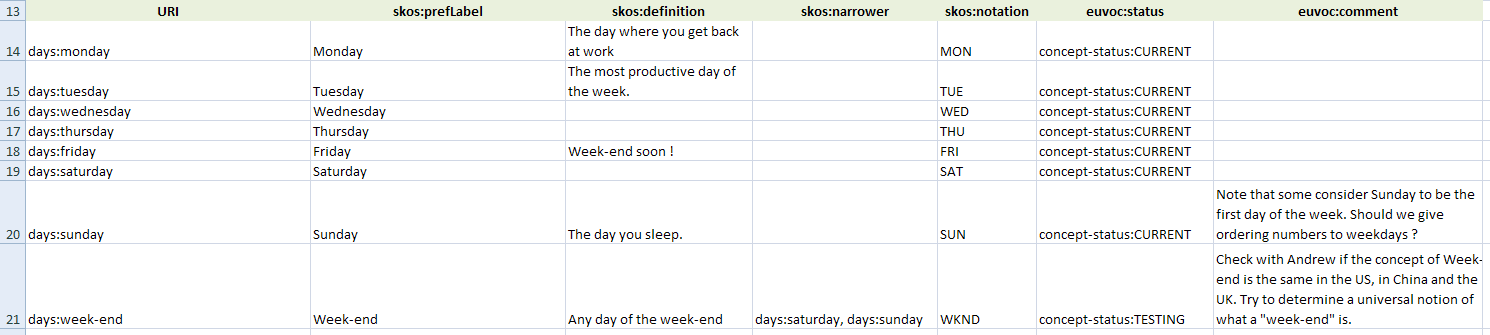
Skos Testing Tool : contrôle qualité
Le SKOS Testing Tool est une interface web permettant de valider la conformité de fichiers SKOS (voir précédent billet). L’outil s’appuie sur qSKOS, qui fonctionne lui en ligne de commande. 27 vérifications peuvent être effectuées sur les données, comme :
- vérification de l’absence de cycle dans la hiérarchie des concepts
- vérification que tous les concepts ont bien un prefLabel
- vérification que tous les concepts sont traduits (dans le cas de thesaurus multilingues)
- …
Combiné avec les sorties alphabétiques/hiérarchiques de SKOS Play, ces vérifications permettent de s’assurer de la qualité des données soit en amont lors des comités de validation du vocabulaire, soit en aval avant la diffusion des données en ligne dans Skosmos.
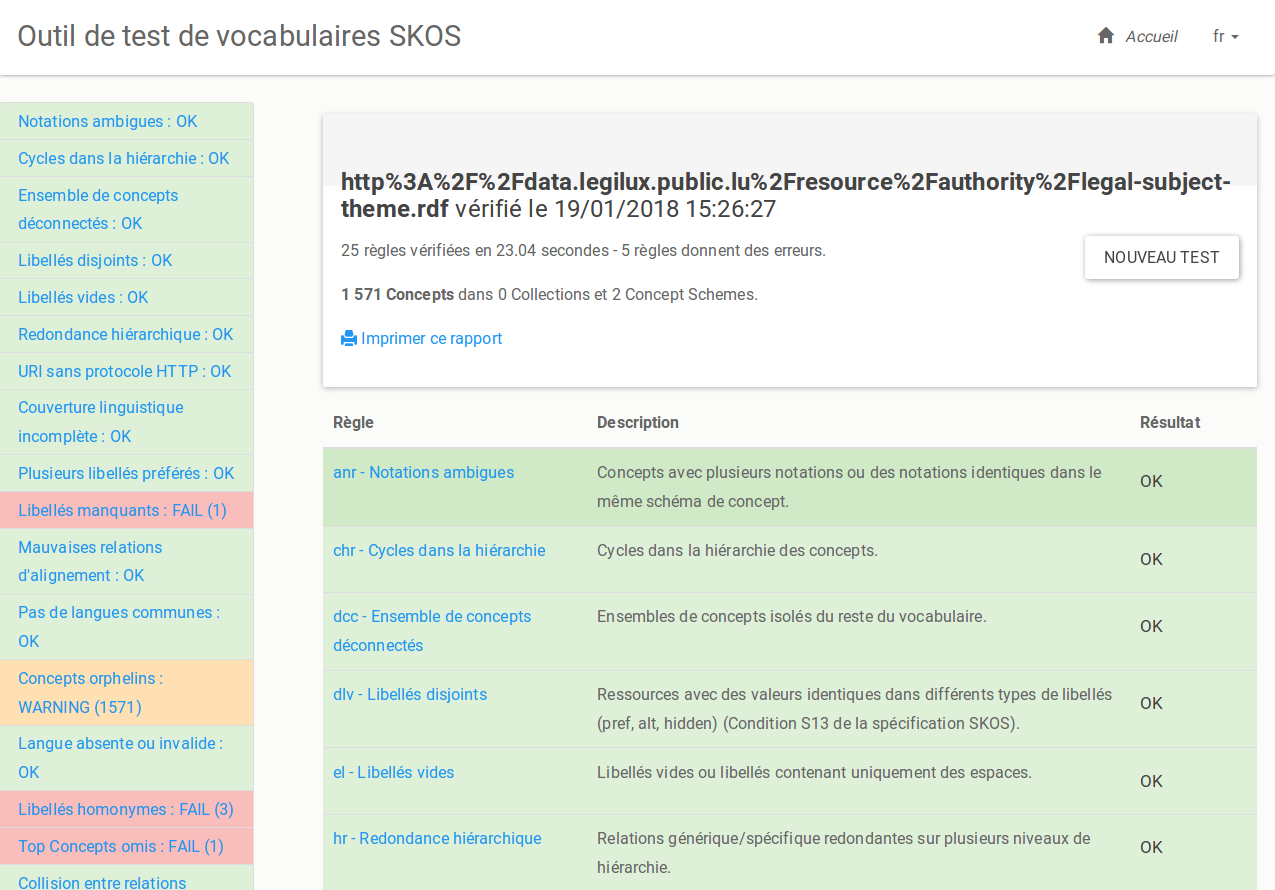
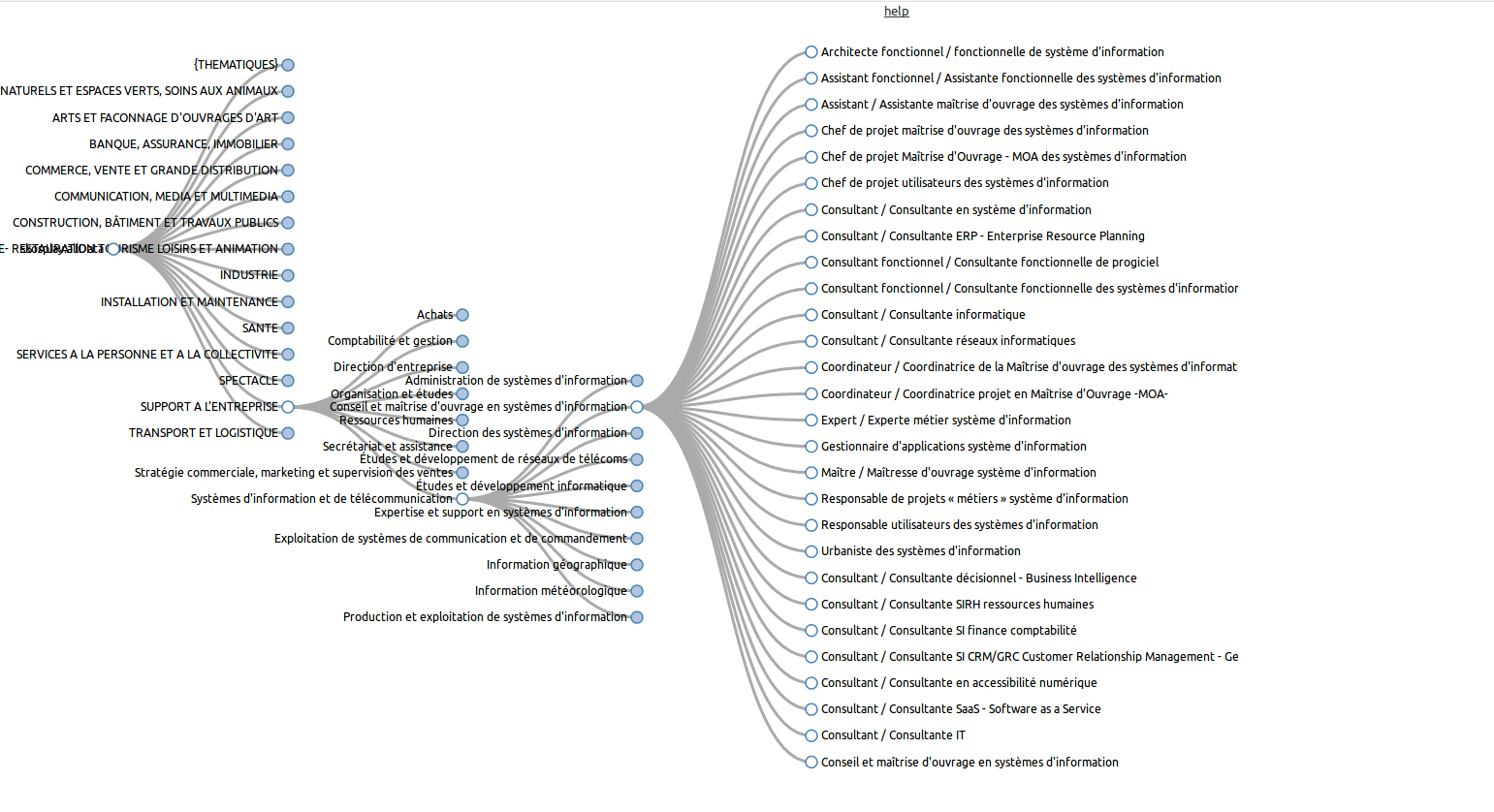
OnaGUI : Alignement semi-automatique
OnaGUI (Ontology Alignment Graphical User Interface) a été développé à l’origine à l’INSERM dans l’équipe de Jean Charlet pour faire de l’alignement d’ontologies médicales, et il a depuis été adapté pour pouvoir aligner des données SKOS.
C’est l’outil le plus accessible et le plus simple d’utilisation pour aligner 2 vocabulaires : on charge un thesaurus à gauche, un thesaurus à droite, et on lance un algorithme d’alignement qui va proposer des correspondances sur la base des proximités des libellés des concepts.
On utilise régulièrement OnaGUI pour illustrer les alignements de thesaurus dans les formations web de données à l’ADBS.
Si on veut utiliser des algorithmes d’alignement plus poussés, on se tournera vers l’API d’alignement de l’INRIA, mais qui demande du développement technique pour être intégrée dans un outil.
Quels outils manquent ?
Quels outils manquent dans l’écosystème des vocabulaires dans le web de données ?
- Probablement des outils faciles à mettre en œuvre pour assister à la création de vocabulaires à partir d’analyse de corpus (détection d’entités, agrégation des mots en concepts, etc.); en connaissez-vous ? IBM Watson ne ferait pas quelque chose comme ça ?
- Des interfaces d’alignement puissantes faciliteraient la mise en réseau des référentiels (des choses comme cultuurlink, mais généralisées);
- Une gestion des versions successives des vocabulaires, avec calcul de deltas, génération automatique de ce qui a changé entre 2 versions, etc;
- Des plugins dans les CMS courants (WordPress, Drupal, etc…) permettant d’importer directement des vocabulaires SKOS, et de les mettre à jour; ça doit bien exister, non ? également des ponts faciles et direct vers SolR et ElasticSearch;
- Mon rêve : un outil d’édition des vocabulaires en mode collaboratif et ouvert poussé, en mode SaaS, sans différence entre l’environnement d’édition et de publication, permettant de faire collaborer une communauté plus large que quelques éditeurs experts; ça viendra un jour !
Et vous, quels outils vous manquent ?
(Illustration de l’article : « Atelier Heilmann Ducommun pour la construction de machines-outils » Gallica http://gallica.bnf.fr/ark:/12148/btv1b10201510v)
Next Post: Outil de test de vocabulaires SKOS


Merci pour cette liste, jusqu’à maintenant je travaillais avec ce bon vieux excel mais je vois que des outils open source sont peut être plus efficaces. Skos à l’air de proposer une suite d’outils très efficaces, à tester…
Le bon vieux Excel est incontournable mais reste un silo de données : les référentiels dans Excel sont difficilement partageables ou réutilisables dans d’autres contextes. Surtout ils ne sont pas « orientés web », avec des URIs et des alignements vers d’autres référentiels. Ce qui est important, dans une perspective de données liées, c’est de prévoir la _publication_ de ces référentiels prisonniers d’Excel en SKOS dans le web de données; c’est pour cela que le convertisseur Excel-vers-SKOS mentionné dans l’article est important.
SKOS est avant tout un _modèle de publication_ des vocabulaires – peu importe la façon et les outils utilisés pour créer ce référentiel au départ; et en même temps c’est aussi un _modèle de travail_ sur les vocabulaires, c’est-à-dire un modèle de données sur lequel les outils de gestion peuvent s’appuyer pour proposer leurs fonctionnalités.
Bonjour,
Merci bien pour cet état des lieux de l’ecosystème open source. J’ai publié récemment un petit article sur le blog qui peut être complémentaire sur ginco: https://www.biblibre.com/fr/blog/ginco-entre-chez-biblibre/
Bonne continuation.
Claire.
Merci. C’est bien d’avoir des retours d’expérience sur Ginco.
Sur les outils d’alignement on me signale 2 outils (sur lesquels je n’ai pas d’expérience personnelle) : Yam++ http://yamplusplus.lirmm.fr et SILK http://silkframework.org/ (qui fait bien plus que de l’alignement)
Many thanks for this great blog, if you are just starting out with vocabularies / ontology where would recommend starting?
Hello Phil
Nice to see people from BIM stopping by ! (I happen to hear about BIM a lot because I share my office with architects and engineering companies). I would love to know more about how controlled vocabularies are integrated in BIM.
If you are starting :
Cheers
Thomas,
Many thanks for the links, just working through the SKOS primer (very technical), the building information modelling community, has been focused on a 3d models containing all the information related to a construction project. I never thought this would be the case as it would be very difficult to manage a 3d model with that much data.
Currently exploring SKOS and RDF with eprints.(see WIP eprints.bimcoordiantor.co.uk One of the missing pieces to the BIM journey maybe a thesaurus of building vocabularies, am hoping to reuse a network map I put together over the last couple years into a SKOS in which documents could be ‘tagged’ with a subject and linked to other data, may come back to on some advice.
Here a link to the network graph https://graphcommons.com/graphs/76050aab-5ac6-4c5b-8267-12235741bb22
Nice network graph ! Feel free to come back for some advice.
Tematres est aussi pratique et très léger, cela peut constituer un premier pas ? Il est pourtant bien cité sur http://labs.sparna.fr/skos-play/about?lang=fr et dispose d’une interface d’édition et de publication combinée (même si depuis Diego a rajouté PortalThes pour la publication). Du coup, je me demande, y-a-t-il une raison pour ne pas le faire figurer ici ? Des soucis à corriger sur l’export SKOS ?
Tout à fait ! merci de ce complément. Tematres (http://www.vocabularyserver.com/) est effectivement un bon outil pour une entrée en matière, sur quelque chose de « léger » comme vous dites.
La seule raison de ne pas le faire figurer ici est mon manque de retour d’expérience dessus ! En particulier je ne connais pas la qualité de son export SKOS; il _pourrait_ y avoir des limites fonctionnelles sur des fonctionnalités « advanced » (droits d’accès fin, assistance aux alignements, facettes, etc.) dont tout le monde n’a pas besoin, mais dans un benchmark des outils Tematres a toute sa place.
Bonjour,
je vous invite à lire le résultat de l’enquête auprès de la communauté internationale qui travaille avec les données d’agriculture et alimentation. Ce travail, réalisé dans le cadre de la Research Data Alliance, a eu comme objectif de produire des recommandations pour développer les approches sémantiques dans notre domaine. Un des constats est que nous manquons cruellement d’outils faciles à prendre en main par des non experts et qui permettent d’intégrer des ressources existantes (dans un objectif d’interopérabilité notamment) .
Pour en savoir plus : https://www.rd-alliance.org/group/agrisemantics-wg/outcomes/39-hints-facilitate-use-semantics-data-agriculture-and-nutrition
N’hésitez pas à commenter !
Merci Sophie, le rapport donne effectivement un bon état des lieux et des recommendations utiles pour les développements futurs. On en recause sûrement à l’occasion. Concrètement, vois-tu des premiers « petits pas », ou « quick wins » qui pourraient aider, notamment par rapport aux outils mentionnés dans le post ?
J’avoue découvrir ce monde, et j’ai du mal à le comprendre.
Bien sur, il est question de standards. Mais à chaque site web, à chaque blog, j’ai l’impression de découvrir le nom d’un nouvel outil spécifique, le nom d’un nouveau standard, le nom d’une nouvelle « library » pour interroger les fichiers…. adaptés à chaque cas spécifique.
Si bien que le mot « open » (datas) se transforme, dans les faits, en parcours du combattant pour accéder aux données d’une manière exploitable. Il faudra bientôt une machine (virtuelle) pour chaque domaine concerné, envahie de dizaines d’outils spéficiques, et obsolètes au bout de quelques mois.
J’ai récupéré un fichier rdf en libre accès depuis un site d’une administration. Oui, c’est facile de le « lire » si on pense que « lire » signifie afficher un fichier sur l’écran. Mais lire un fichier de données, ce n’est pas cela. C’est utiliser un outil qui saura présenter les données de manière organisées et exploitables.
Et c’est là que je coince.
Je coince d’autant plus quand j’entends parler d’Excel (je n’ai rien contre) qui me parait inadapté dès que la quantité de données à gérer dépasse quelques milliers d’enregistrements, sans parler des problèmes de codage de caractères. Ce que je cherche, sans le trouver, c’est l’outil qui sait gérer ces nouveaux formats extrêment verbeux (rdp, et cie) enregistrement par enregistrement ? Ai-je si mal cherché, c’est possible.
Ces fichiers sont avant tout des tables, comme depuis toujours dans n’importe quelle base de données, mais trouver un outil qui sait les lire comme ce qu’elles sont destinées à être, des tables (au sens « exploitable » du terme), s’avère, en fait, de la mission impossible.
J’ai surement manqué une étape : la notion de table, en informatique, est très ancienne Et pourtant, il est bien difficile de trouver, dans le moindre blog ou site web, l’information qui nous guide vers un outil qui saura lire ces fichiers pour ce qu’ils sont, des tables. Et c’est pas faute d’avoir cherché. C’est vrai, il reste la « ligne de commandes » : mais je n’ai pas l’ambition de faire l’application du siècle, ni le désir de passer des semaines à réinventer la roue.
Bref : si quelqu’un peut me donner un outil qui permet d’exploiter un fichier « rdp » comme un fichier de données (et pas juste comme un document affiché sur l’écran), comme on pouvait le faire avec tout fichier de type « texte » il y a plus de quarante ans, et si possible sous windows 10 (puisque l’article parle d’Excel), je l’en remercie d’avance.
Bonjour, réponse courte : OpenRefine https://openrefine.org/ ou GraphDB (http://graphdb.ontotext.com/)
Réponse longue : je ne sais pas si je peux répondre; 1/ le billet parle d’outils pour la _publication_ de données RDF, vous questionnez sur les outils d’_exploitation / réutilisation_. 2/ Vous parlez de fichiers « RDP », dans le web de données on parle de RDF, du coup j’ai un doute, mais mettons ça sur le compte d’une faute de frappe 3/ les fichiers RDF sont par nature des fichiers de données brutes destinées à des programmes, des bases de données, des machines, et ne sont pas fait pour être directement exploités « par l’humain ». 4/ vous écrivez « ces fichiers sont avant tout des tables »… c’est peut-être le cas pour le fichier de données particulier que vous avez téléchargé (vous pouvez indiquer lequel), mais de façon générique RDF encode un _graphe_ et pas du tout des tables (c’est ce qui fait la difficulté de votre situation), et il n’y a pas de notion d’_enregistrement_ en RDF.
La question serait de toutes façons plus à poser par le biais du portail open data de l’administration en question. Typiquement certains producteurs de données doublent les formats de diffusion de leurs données et proposent un format de fichier CSV simple en combinaison avec un format de fichier RDF plus riche.
Vous écrivez « …un outil qui permet d’exploiter un fichier « rdp » (je lis : RDF)… comme on pouvais le faire avec tout fichier de type « texte » il y a plus de 40 ans… » : que faisiez-vous avec des fichiers de type texte il y a plus de 40 ans pour l’exploiter exactement ? Excel ? une base de données ? des expressions régulières ?
Si vous cherchez un espèce de super-Excel pour ouvrir et manipuler votre fichier RDF, utilisez OpenRefine (https://openrefine.org/); Si vous cherchez une base de données pour interroger votre fichier RDF, utilisez une base de données RDF (« triplestore ») comme GraphDB (http://graphdb.ontotext.com/) mais j’ai envie de vous dire d’essayer de voir si les données que vous convoitez n’existeraient pas dans un autre format.