Identifier, décrire et relier les lois sur le web ELI…
Nakala : from an RDF dataset to a query UI in minutes – SHACL automated generation and Sparnatural
Here is a usecase of an automated version of Sparnatural submitted as an example for Veronika Heimsbakk’s SHACL for the Practitioner upcoming book about the Shapes Constraint Language (SHACL).
“
The Sparnatural knowledge graph explorer leverages SHACL specifications to drive a user interface (UI) that allows end users to easily discover the content of an RDF graph. What is the best way to make this UI-oriented SHACL specification ? if a SHACL specification for the knowledge graph structure already exists, can it be used directly ? does it require customization ? or is the Sparnatural SHACL spec completely decoupled from an existing knowledge graph spec ? and what if no SHACL spec exists at all ?
We faced all these different situations while deploying Sparnatural, and used various approaches to produce a satisfying end-user oriented specification. In particular, the Nakala repository is one of the latest graph for which Sparnatural was deployed. Nakala is a data repository that aims to preserve and disseminate data produced by French research projects in the Humanities and Social Sciences, in compliance with the FAIR principles. Nakala is a service offered by Huma-Num, a research infrastructure dedicated to the digital humanities. The Nakala knowledge graph contains `dcterms` metadata provided by researchers to describe the resources they upload. Additional non-dcterms metadata can also be provided. The metadata varies in quality and quantity depending on the researcher. When exposed in a SPARQL endpoint, resources, collections of resources and agents are described using the Europeana Data Model (EDM).
As the EDM dissemination channel for Nakala was new, no SHACL specification existed for it. We could have designed one for Sparnatural from scratch, but the choice was make to generate it automatically, with no human intervention. This was for three reasons : ease of configuration, flexibility in maintenance over time, and pedagogical reason, as it was important to explain the structure of the graph to target users.
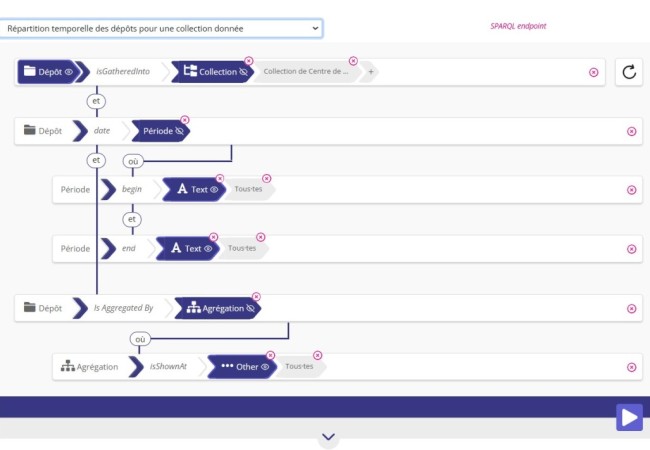
Sparnatural UI
Let’s first have a look at what the Sparnatural UI looks like on an example from Nakala:

Once you know that « ProvidedCHO » stands for « Provided Cultural Heritage Object », and that « asWKT » encodes the location of a Place, you will be able to understand that the query searches for all ProvidedCHO entries gathered into a certain collection (« Cartes Université Bordeaux Montaigne » – a collection of maps), and selects their location and an optional description (and yes, the results of this query are displayed on a map, but that’s out of scope).
SHACL is derived automatically
In this project we wanted the shortest path from the graph to the query UI. Hence we used a SHACL generation algorithm, available in SHACL Play. By issuing SPARQL queries on an RDF graph, the algorithm determines the NodeShapes (targeting the classes used as values of `rdf:type`), and PropertyShapes (from all predicates used on instances on each class) of the model, with their node kinds, datatypes, class range, and cardinalities. It generates `sh:or` constraints when multiple datatypes or ranges are found. Note that in the case of Nakala a large variety of ranges are used, since the data comes from very open user inputs : the same `dcterms` property can be either an IRI or a Literal, with varying datatypes.
In addition, the algorithm computes some statistics on the dataset : the number of targets of each NodeShapes, the number of occurrences and the number of distinct values for each property shapes. The statistics are expressed using the `void` vocabulary, and `dcterms:conformsTo` is used to link void partitions to the corresponding shapes.
The SHACL Play documentation tool was then used to generate a report of the generated SHACL combined with the statistics. A few errors were spotted in the exported data, and fixed. We also saw that around 70 properties were present only a few times out of 700.000+ ProvidedCHO records. These properties were applied by probably a single or very few researchers when describing their data. It was decided to filter them out to keep the final UI simple, with an extra filtering step : based on statistics, property shapes used less than 0.1% of the number of targets of their node shapes are removed.
Here is a screenshot of the report : the right column shows the number of distinct values, and the column before is the number of total occurrences; we can immediately see that `dct:isReplacedBy` occurs only once, and `dct:isRequiredBy` occurs 81 times. They will be filtered out.

Sparnatural reads SHACL
Sparnatural can then read the SPARQL specification, together with the dataset statistics. When designing a query, value selection widgets for literal properties are determined by looking at the `sh:datatype` constraint (for number, dates, boolean, or map widgets). For IRI properties, statistics are used to distinguish between list and autocomplete widgets. Predicates with less than 500 distinct values will use a dropdown list, and those with more will use an autocomplete search field. The range is determined by reading `sh:class` or `sh:node`. The label to show in dropdown lists or to search on autocomplete field is determined by looking at a `dash:propertyRole = dash:LabelRole` annotation.
How about labels ? Sparnatural can read them from classes and properties of the original OWL file, if provided with it. Otherwise local names of target classes or predicates are used.
Other configuration techniques
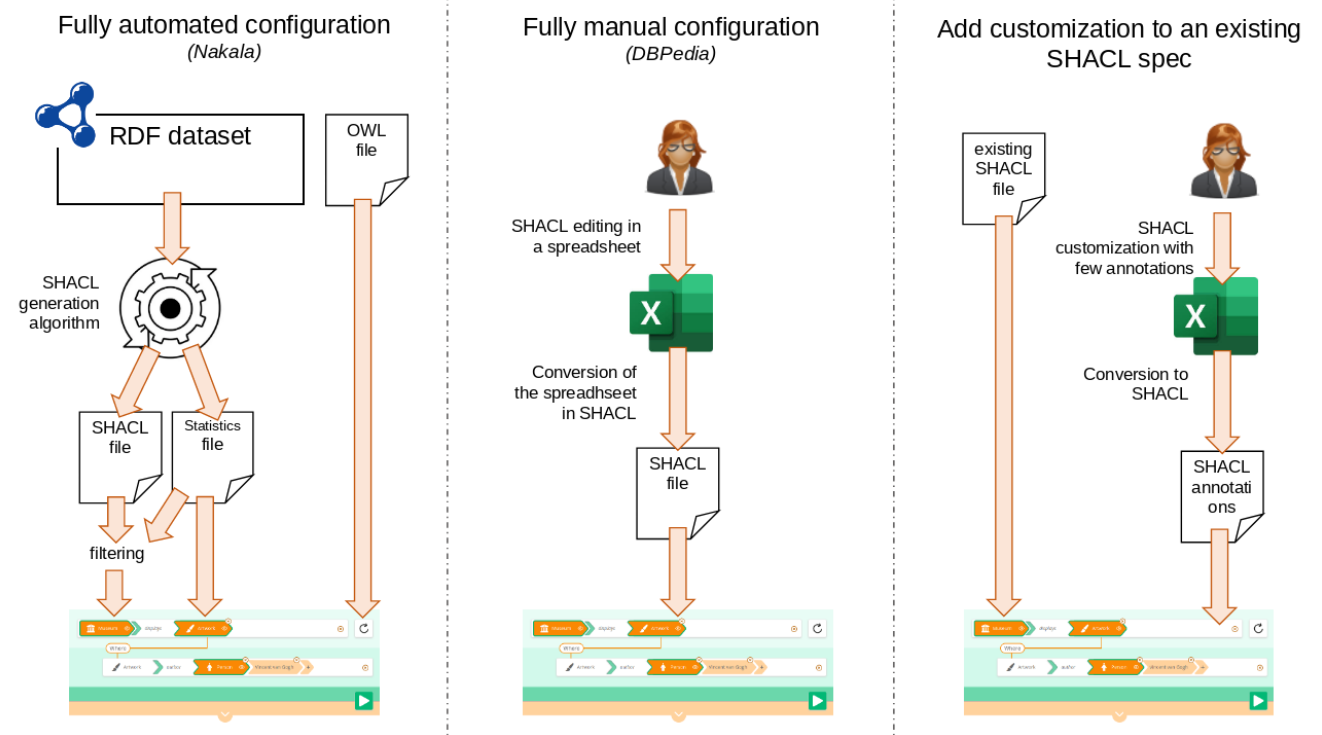
Other Sparnatural deployments, such as the DBPedia demo are designed in SHACL from scratch, using spreadsheets. This requires more manual work, but has the advantage of tailoring the UI to exactly what needs to be shown, including user-oriented labels/tooltips/icons, hiding some properties, taking shortcuts or declaring inverses using property paths, etc. In the case of DBPedia, no SHACL spec exists, and deriving it automatically for the entire graph would probably not make a lot of sense, hence the necessity for a manual design.
For other projects we are working on a third configuration technique : a SHACL spec that describes the exact content of the graph is first built. It is used to publish the documentation of the model and to validate the data. A separate shapes file containing a Sparnatural-specific configuration layer is then added on top of it. That layer can hide shapes by applying an `sh:deactivated` annotation on them, can specify the UI widgets to use, add additional `dash:LabelRole` flags, add shortcut or inverse properties, etc.
The 3 configuration paths are shown in the following diagram:
Your query UI in minutes
We combined 4 tools (all open-source) : an algorithm to generate a « profile » in SHACL of an RDF dataset, a statistical report generator, a SHACL filter based on statistics, and the Sparnatural query UI. The ability to generate the SHACL profile and review it in the report provided a way to understand the structure of the data in a matter of minutes, while hours would have been necessary with SPARQL queries, without a guarantee of completeness. The provision of the query UI was made by dropping the SHACL file and the statistics to Sparnatural, without manual intervention. This shows the pivotal role of SHACL for data quality and model-driven approaches for knowledge graphs projects.
”
We look forward to reading Veronika’s book, and you ?