


(english summary scroll down) Je continue à creuser le sillon…
Alimenter Talend avec SPARQL (sur Wikidata)
Dans le billet précédent nous avons vu comment Talend pouvait être utilisé pour convertir des données existantes vers du RDF/XML pour alimenter un graphe de connaissances. Ici nous allons voir… exactement l’inverse ! Comment alimenter Talend avec une requête SPARQL ? En d’autres termes comment votre graphe de connaissances RDF pourra servir d’entrée à un traitement de conversion de données pour exporter des données tabulaires, alimenter d’autres bases, ou se combiner avec d’autres flux.
Le principe est simple : arriver à exécuter une requête SPARQL puis traiter les résultats correspondants pour en faire un tableau de données. Ce tableau de données pourra ensuite être exporté, combiné, enregistré, comme vous le souhaitez.
Pour illustrer cela nous allons interroger Wikidata au travers de son service d’interrogation SPARQL en utilisant sa première requête d’exemple qui récupère… les chats !
La requête est la suivante, et voici le lien direct pour l’exécuter dans Wikidata :
SELECT ?item ?itemLabel WHERE { ?item wdt:P31 wd:Q146. SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". } } LIMIT 10
Vous pouvez télécharger le job présenté ici dans ce repository Github d’exemple, et l’importer directement dans Talend.
Nous allons utiliser les composants Talend suivant :
- tRESTClient envoie des requêtes HTTP à un service REST et retourne les réponses; en effet, un service SPARQL n’est ni plus ni moins qu’une URL où on passe un paramètre “query”, comme spécifié par le protocole SPARQL.
- tExtractXMLField pour traiter le format XML de réponse SPARQL; en effet, le format de réponse d’un service SPARQL est lui-aussi standardisé, en XML ou en JSON;
- tFileOutputDelimited pour simplement écrire le résultat dans un fichier de sortie.

Création d’un Job
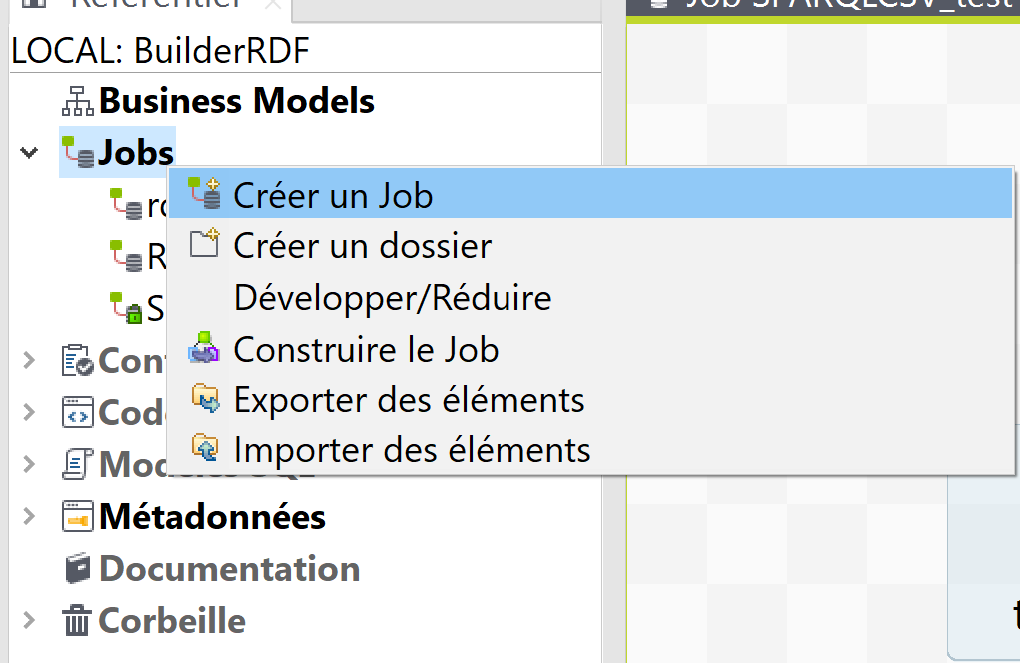
Pour commencer, vous devez créer un nouveau job.
- Faite un clic droit sur Jobs dans le panneau de gauche. choisissez l’option Créer un Job.
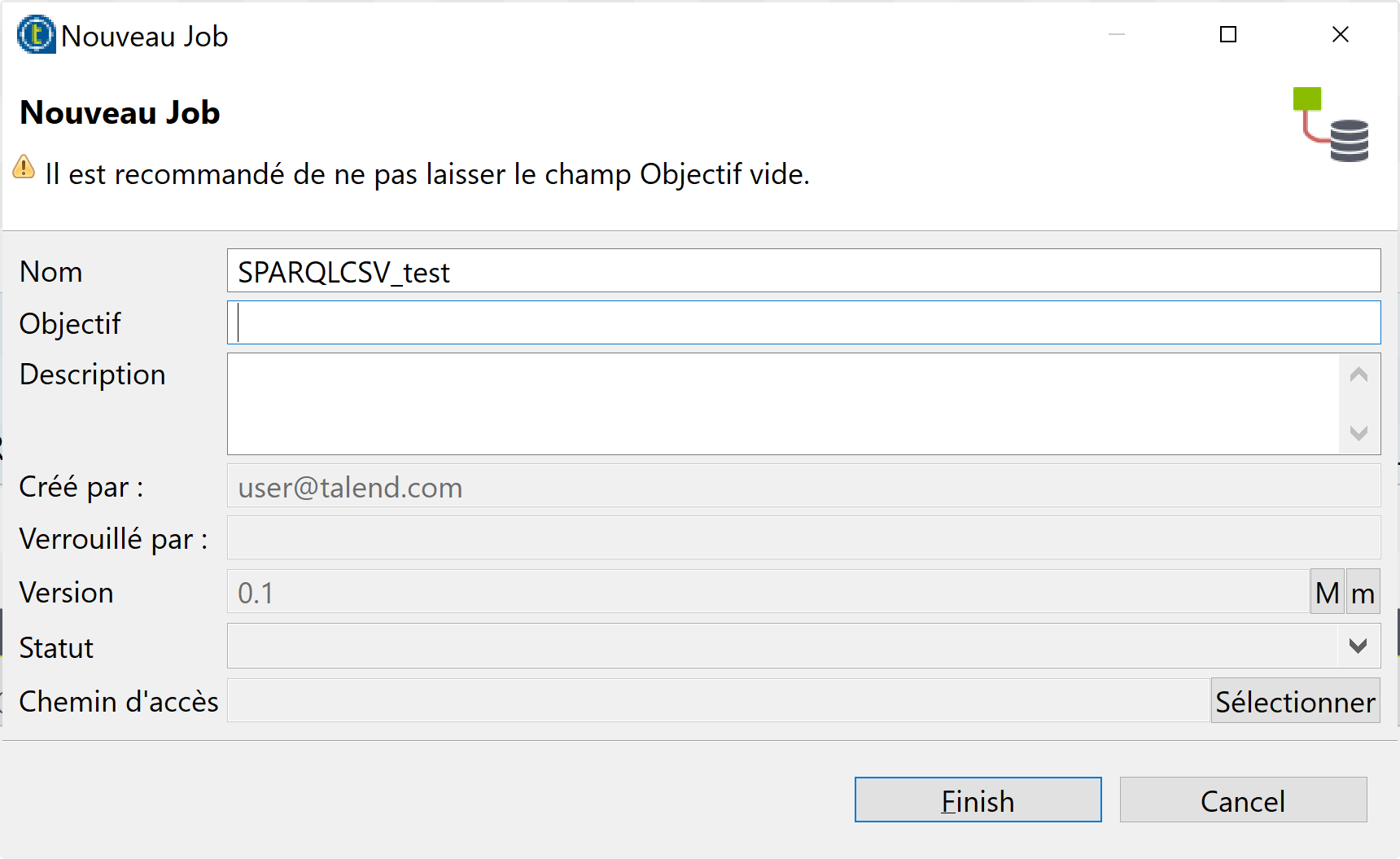
- Remplissez les champs nécessaires de la fenêtre Nouveau Job et cliquez sur le bouton finish.
Appel SPARQL avec tRESTClient
- Ajoutez au job le composant tRESTClient.
- Cliquez deux fois sur le composant tRESTClient, allez à la propriété Paramètres simple et remplissez les paramètres suivants:
- URL: L’URL du service SPARQL de Wikidata est https://query.wikidata.org/sparql .
- Méthode HTTP: Choisissez la méthode HTTP GET
- Paramètre de la Requête: Nous devons ajouter le paramètre “query”, cliquez sur le bouton plus [+], et dans la colonne Nom entrez “query”. Dans la colonne Valeur vous allez saisir la requête SPARQL.
Attention! La requête SPARQL est une chaîne de caractères Java, vous devez donc : 1/ L’entourer avec des guillemets doubles 2/ ajouter le caractère d’échappement \ avant les guillemets dans la requête et 3/ écrire la requête sur une seule ligne. Voici la chaîne de caractères correspondante :
“SELECT ?item ?itemLabel WHERE { ?item wdt:P31 wd:Q146. SERVICE wikibase:label { bd:serviceParam wikibase:language \"[AUTO_LANGUAGE],en\". } } LIMIT 10”
Transformation des résultats SPARQL avec tExtractXMLField
- Ajoutez dans le projet un composant tExtractXMLField.
- Connectez le composant tRESTClient au tExtractXMLField.
Nous allons paramétrer le tExtractXMLField :
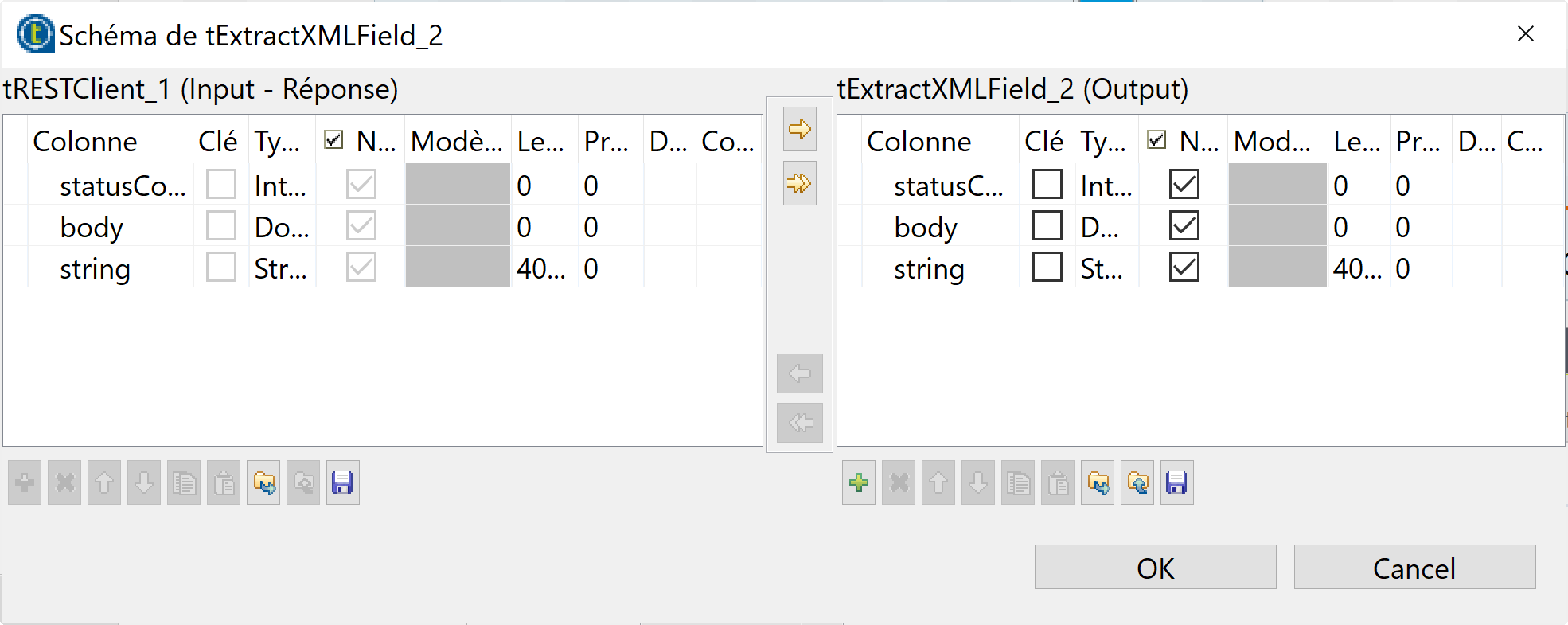
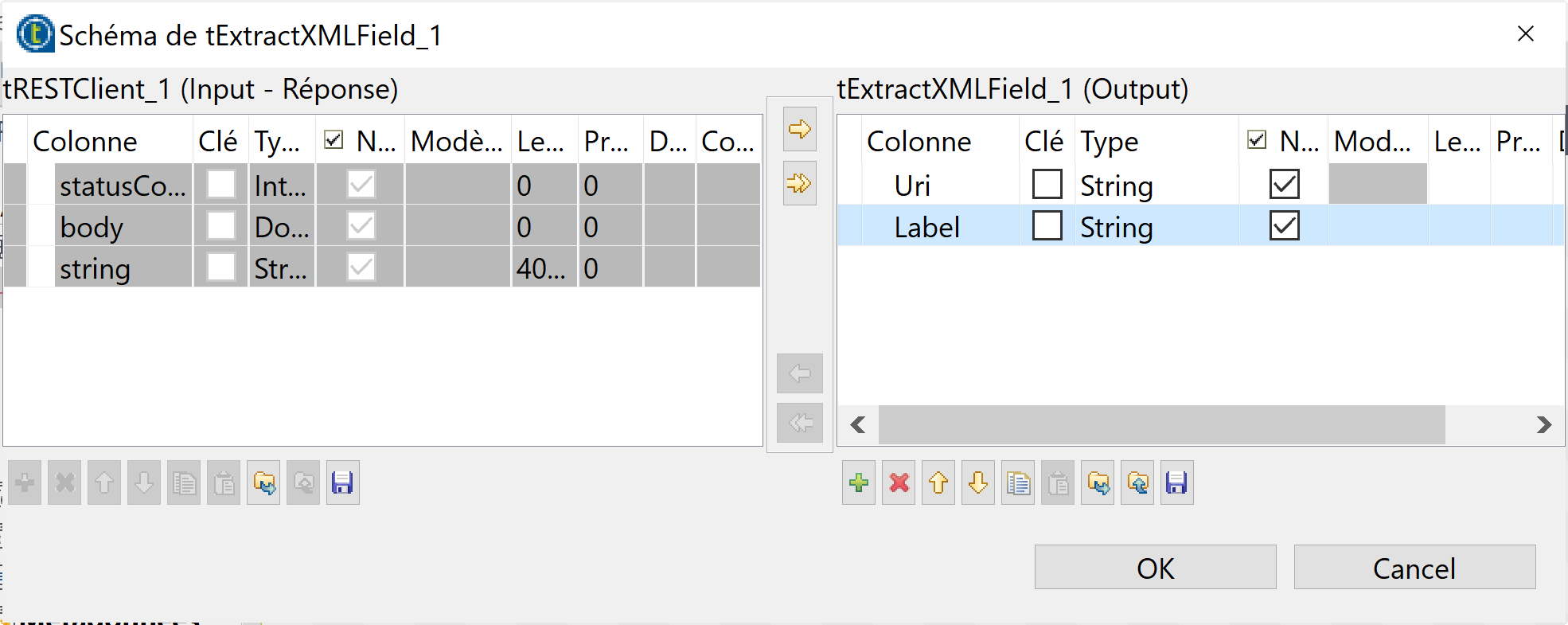
- Cliquez sur le bouton Modifier le schéma pour ouvrir la fenêtre des colonnes d’entrée et sortie du composant tExtractXMLField.
- Ajoutez deux nouvelles colonnes Uri et Label de type String avec le bouton plus [+] et cliquez sur le bouton Ok.
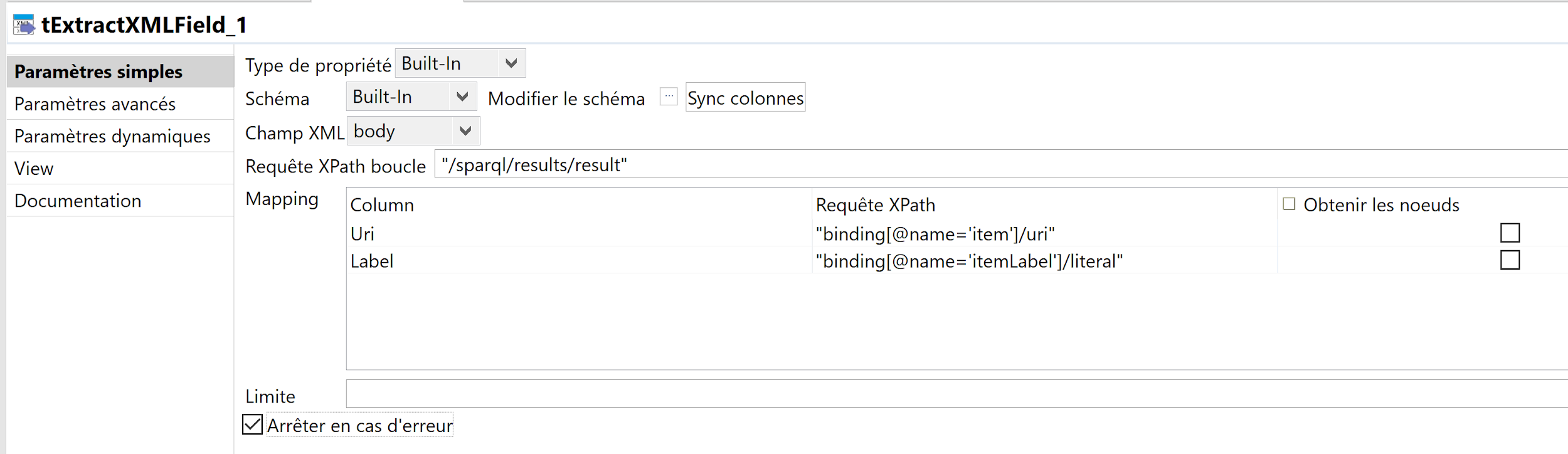
- Allez à Paramètres simple et modifiez les options suivantes:
- Champ XML: Choisissez le champs “body”, qui est le champ qui contient la réponse à l’appel SPARQL du composant précédent;
- Requête XPath boucle: Saisissez « /sparql/results/result » qui est d’après la spec du format de résultat SPARQL le chemin vers chaque ligne de résultats dans la réponse.
- La table Mapping : c’est ici que tout se joue !!! ce mapping va vous permettre d’associer les colonnes de votre résultat SPARQL au champs de sortie du composant, par le biais de chemins XPath:
- Pour la colonne Uri la valeur de la colonne Requête Xpath sera « binding[@name=’item’]/uri »
- pour la colonne Label la valeur de la colonne Requête Xpath sera « binding[@name=’itemLabel’]/literal ».
- Si la requête SPARQL retournait plus de colonnes, il faudrait ajouter ici les mappings correspondants pour alimenter les autres colonnes du résultat.
Génération du fichier de sortie
- Ajoutez le composant de sortie tFileOutputDelimited.
- Connectez le composant tExtractXMLField au composant tFileOutputDelimited.
- Paramétrez le composant dans la section de Paramètres simple → Nom de fichier: le chemin dans lequel vous souhaitez sauvegarder le fichier de sortie.

Lancer le Job
- Allez à la section Exécuter.
- Cliquez sur le bouton Exécuter.
Profitez !
Naviguez vers l’emplacement du fichier pour le récupérer.
Et voilà le résultat :
Uri;Label http://www.wikidata.org/entity/Q378619;CC http://www.wikidata.org/entity/Q498787;Muezza http://www.wikidata.org/entity/Q677525;Orangey http://www.wikidata.org/entity/Q851190;Mrs. Chippy http://www.wikidata.org/entity/Q1050083;Catmando http://www.wikidata.org/entity/Q1201902;Tama http://www.wikidata.org/entity/Q1207136;Dewey Readmore Books http://www.wikidata.org/entity/Q1371145;Socks http://www.wikidata.org/entity/Q1386318;F. D. C. Willard http://www.wikidata.org/entity/Q1413628;Nora
Vous savez donc maintenant comment alimenter Talend à partir d’une base accessible en SPARQL, en quelques clics et sans code ! Cela permet de valoriser votre graphe de connaissances pour l’intégrer dans le reste du système d’information.
Next Post: Générer du RDF avec Talend (un tutorial)

