
La BNF organisait le 10 juillet 2018 un atelier "Données…

VIVO / VITRO : solution d’édition et de publication RDF basée sur une ontologie
Théoriquement, RDF est un format d’échange de données. Ce qui signifie que dans les architectures informatiques les données RDF transitent d’applications en applications, mais ne sont généralement pas à l’intérieur des applications. Celles-ci peuvent rester basées sur des bases relationnelles classiques, et, si besoin, exposer leurs données en RDF ou SPARQL via des middlewares comme D2RQ, ou via des exports spécifiques. Si bien que, théoriquement, il n’y a pas de besoin de modifier/créer nativement des données RDF…
Théoriquement, car, dans certains cas, on peut vouloir baser une application directement sur un triplestore RDF (ce qui a bien des avantages), ou bien avoir la possibilité de modifier, via un formulaire, des données RDF, en se basant sur une ontologie OWL particulière.
Et le hic c’est que les briques logicielles pour pouvoir éditer du RDF directement, via des formulaires générés à partir d’une ontologie par exemple, il n’y en a pas des tonnes. En fait j’en connais 2 que j’ai pu mettre en œuvre dans des projets différents : RDForms (anciennement RForms sur l’ancien site Google Code), sur lequel je reviendrai sûrement pus tard, et VIVO, ou plus exactement VITRO.
VIVO est un projet commun de plusieurs universités américaines et en particulier de l’Université de Cornell. L’objectif ? partager et mettre en lien les travaux de recherche des chercheurs de ces universités. Le moyen ? les technologies du web de données, RDF, OWL, SPARQL. L’outil ? VIVO, donc, qui permet de mettre en ligne les descriptions des publications scientifiques, des chercheurs, des conférences, et des labos de tout ce beau monde. L’originalité ? c’est que VIVO est basé sur un triplestore RDF et un moteur SolR pour la recherche, et que ses écrans de navigation et d’édition réagissent directement à une ontologie OWL, que l’on peut éditer directement dans le back-office de l’outil, en rajoutant également des annotations spécifiques pour contrôler certains comportements (comme la séparation des champs en onglets dans les écrans). Côté customisation également, des pages spécifiques peuvent être créées à partir de requêtes SPARQL et de templates Freemarker pour la présentation des résultats; le menu de navigation principal est également paramétrable. Et cerise sur le gâteau, la publication des données en RDF pour chaque fiche, via négociation de contenu, est incluse nativement.
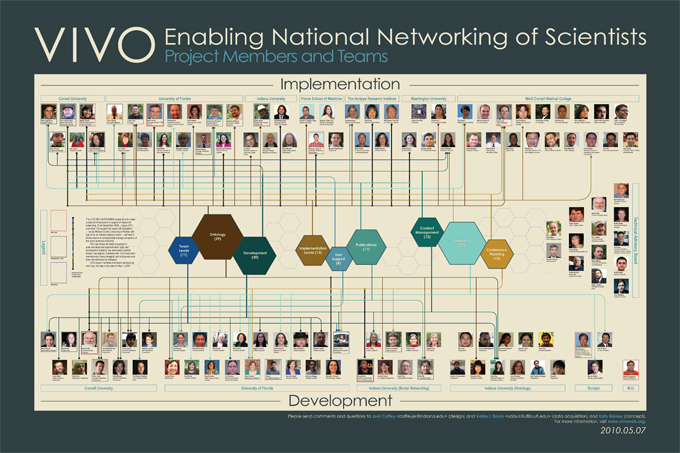
Toutes ces fonctions sont offertes par la brique logicielle VITRO, qui est donc une brique logicielle « nue ». Et VIVO est un paramétrage assez conséquent de cette brique nue, avec une ontologie spécifique sur le domaine de la recherche scientifique, un menu de navigation spécifique (« People » / « Research » / « Organizations » / « Events »), et des écrans d’affichage particuliers, pour le profil d’un chercheur par exemple. En plus certaines visualisations sont incluses, comme une « Map of Science » (carte conceptuelle des thématiques de recherche d’un chercheur ou d’un labo), une navigation géographique par pays, ou un graphe des co-auteurs d’un chercheur. Le mieux est encore d’aller regarder tout cela sur les instances de VIVO actuellement en ligne, comme celle de l’University of Florida ou celle de Cornell (voir la liste de tous les déploiements de VIVO).
L’intérêt pour toutes ces institutions de publier les données brutes de leurs recherche dans un format RDF est de pouvoir 1/ faire des liens entre les données de chaque institution et 2/ mettre ensemble ces données dans un moteur de recherche centralisé, comme cela est démontré par le moteur beta.vivosearch.org qui aggrège et permet de rechercher sur les données de 8 institutions de recherche.
Avec VITRO, on a donc :
- un outil open-source, J2EE, prêt à déployer dans Tomcat;
- une plateforme de navigation / édition / recherche dans un triplestore RDF;
- avec un back-office permettant de modifier directement les données RDF, en se basant sur n’importe quelle ontologie de domaine;
- avec une gestion des comptes utilisateurs et des droits d’accès;
- avec des possibilités de customisation « relativement » aisées pour un développeur Java;
L’idéal serait de pouvoir mettre l’outil à l’épreuve !

Merci.
« L’idéal serait de pouvoir mettre l’outil à l’épreuve ! » Tu penses à quelqu’un en particulier ? ou bien à monter un démonstrateur ?
Bonjour, il semble que l’auteur avait en tête cette collaboration avec l’Inra : http://fr.slideshare.net/SemWebPro/04-edzale
J’en profite pour vous annoncer que la chef de projet côté Inra sera présente lors d’une soirée le 11 mai à Paris pour débattre des annuaires modernes de laboratoire : http://www.deuxieme-labo.fr/article/soiree-debat-sur-la-visibilite-de-la-recherche-francaise-le-11-mai-a-lespace-des-sciences-pierre-gilles-de-gennes-paris-5e/
Bonjour, merci pour cette info sur l’événement. Mon utilisation de Vivo fait effectivement suite à ce projet avec l’Inra que nous avons présenté à Semweb.pro 2014.
Je faisais référence dans le billet à une possible future expérimentation de Vitro, la couche publication/édition RDF pure. J’ai eu l’occasion de pouvoir l’utiliser sur un autre projet dernièrement, et mon retour d’expérience n’est pas 100% positif, cela fera l’objet si le temps le permet d’un futur billet.
Bonjour,
j’aurais aimé connaitre, en quelques mots, quels sont les aspects qui vous amènent à dire que votre retour d’expérience n’est pas 100% positif . Merci beaucoup.
Bien cordialement
– modification des valeurs compliquée (attribut par attribut, pas de formulaire de modification complet d’une entité) et buggée (pas de prise en compte des datatypes dans la version testée)
– paramétrage lourd de l’ordre des propriétés et des onglets (fichier de config compliqué)
– chargement des données très lent
– pas de formulaire de recherche multicritères
Ces remarques ne s’appliquent pas à VIVO mais à VITRO. VIVO ne demande pas/moins de customisations, il dispose de formulaires et d’affichages précablés pour l’ontologie VIVO, et est prévu pour faire de la publication de données et pas de l’édition de données. Nous avons essayer de positionner VITRO comme un outil de back-office/édition alors qu’il est fait pour être un outil de front-office/publication.
Bonjour Thomas,
Ma question est de savoir si on peut charger du SKOS dans VIVO ou VITRO ?
Merci d’avance.
Ps: Merci encore pour la formation à Ivry (ANF Frantiq), c’était très enrichissant.