

DOREMUS est un beau projet de recherche regroupant plusieurs producteurs…
Recherche d’informations : du plein-texte aux ontologies
Il peut être tentant, après avoir lu de la littérature sur les ontologies, de penser qu’elles peuvent solutionner tous les problèmes d’un système de recherche d’informations comme un moteur de recherche d’entreprise (type SolR). Mais il ne faut pas perdre de vue que, dans la conception d’un tel système, des problématiques plus fondamentales existent. Et qu’il est nécessaire de d’abord bien traiter ces problématiques avant de se lancer dans la conception d’une ontologie et sa mise en œuvre dans le système.
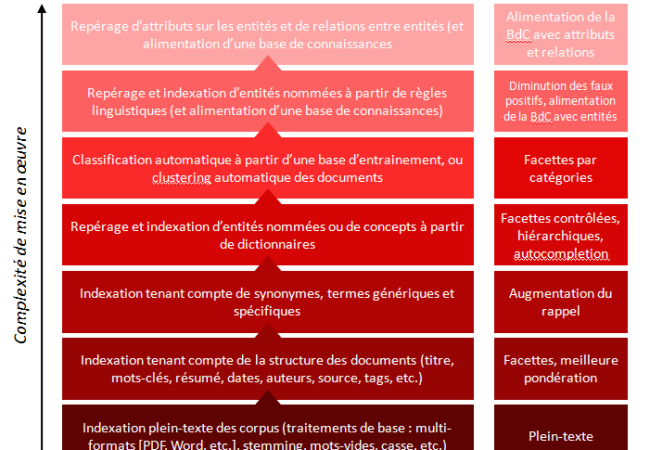
Si vous avez un corpus documentaire, comme une base d’articles scientifiques, et que votre besoin est d’accéder aux informations dans ce corpus, ne commencez pas par développer une ontologie. C’est ce que j’ai essayé de résumé sur ce schéma qui donne, par ordre croissant de complexité de mise en œuvre, les problématiques à traiter dans le couplage entre de la recherche non-structurée et des vocabulaires métiers structurés.
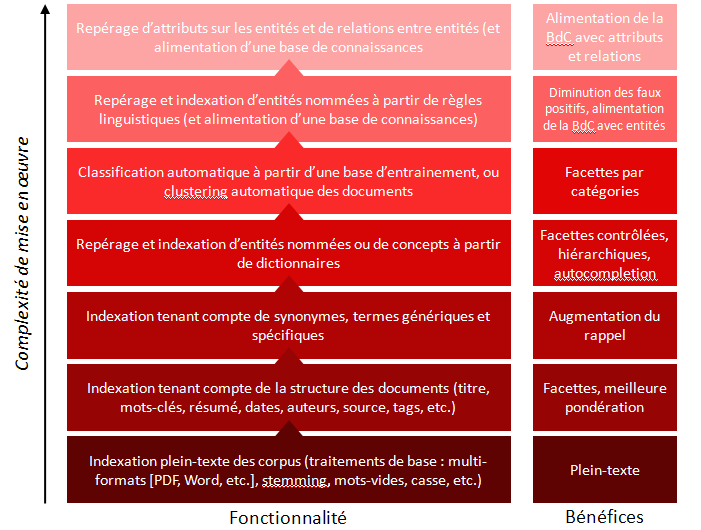
Par ordre croissant de complexité, et de bas en haut sur l’image :
Niveau 1: traiter le plein-texte
S’assurer que l’indexation est capable de prendre en compte tous les formats de fichiers (HTML, PDF, Word s’il y a lieu); qu’elle ne tient pas compte des majuscules/minuscules, qu’elle traite correctement les mots vides (voir par exemple la liste des mots vides qu’utilise SolR), qu’elle fait un stemming correct (l’algorithme de stemming peut être ajusté pour être plus ou moins « aggressif »).
Bénéfice de ce premier niveau : vous pouvez chercher en plein-texte sur votre corpus.
Niveau 2 : tirer partie de la structure des documents
L’idéal ici est d’avoir des documents déjà structurés, typiquement en XML. De façon à pouvoir faire 2 choses : d’une part, pondérer certains champs (donner plus d’importance au titre qu’au reste, typiquement) et d’autre part, si certains champs contiennent un nombre limité de valeurs possible (des champs de tags, de mots-clés, d’année, de type de document, de source, etc.), pouvoir en faire des facettes.
Bénéfices de ce deuxième niveau : vous avez des résultats plus pertinents car mieux pondérés, et vous pouvez filtrer sur certains critères supplémentaires;
Niveau 3 : injecter du vocabulaire métier
Sans aller jusqu’à des ontologies très structurées (au sens logique, ou intelligence artificielle, du terme), on peut bénéficier dans le moteur de l’injection de terminologies ou de thesaurus. Cela permet de déclarer des équivalences entres des mots ou des groupes nominaux, et ainsi de faire augmenter le rappel du moteur : si l’utilisateur cherche sur un synonyme, ou un acronyme présent dans le thesaurus, il va trouver les documents qui contiennent les termes préférentiels ou les termes complets.
Bénéfices de ce troisième niveau : une augmentation du rappel, et éventuellement l’utilisation du vocabulaire métier pour l’autocompletion de la recherche ;
Niveau 4 : indexation des entités et des concepts métier
Là-encore, on utilise la terminologie métier, mais, en plus d’étendre les fonctionnalités de la recherche plein-texte, il s’agit de réaliser une indexation des documents sur les entités ou les concepts métiers. Dans les systèmes de recherche qui nous intéressent ici, cette indexation doit être automatique et ne pas faire intervenir de validateur humain. Il va donc s’agir de repérer dans les textes les occurrences des entités ou des concepts du vocabulaire métier. Un outil de text-mining est typiquement nécessaire pour cela (par exemple Gate), a minima pour pour traiter les singuliers/pluriels, masculins/féminins, conjugaisons, etc. Attention au niveau de qualité de ces outils, et au paramétrage des règles grammaticales qui prennent du temps. A partir de là, on pourra présenter une facette complètement basée sur le vocabulaire métier, donc éventuellement hiérarchique.
Bénéfices de ce niveau : des facettes hiérarchiques sur le vocabulaire métier;
Niveau 5 : classification ou clustering automatique
Certains outils proposent soit de classifier les corpus sur des catégories prédéfinies (typiquement l’IPTC pour les articles de presse), soit de faire du clustering de documents à la volée, en déterminant automatiquement les clusters au fur et à mesure. C’est par exemple le cas de la belle application de visualisation de données sur l’actualité des jeux vidéos réalisée par Dataveyes et Antidot. Ici, on est déjà sur une problématique avancée nécessitant d’avoir un outil précis.
Bénéfice : des facettes additionnelles, par catégories;
Niveau 6 : indexation à partir de règles linguistiques
C’est la même idée que le niveau 4, à savoir le repérage d’entités ou de concepts dans les textes, mais non plus à partir d’une liste prédéfinie, mais en analysant la structure grammaticales des phrases (« le sujet d’un verbe d’action qui commence par une majuscule est sûrement une personne »). Autant dire qu’ici, le travail de paramétrage d’un analyseur grammatical est très coûteux. Le bénéfice qu’on en tire est de pouvoir trouver de nouvelles entités, donc d’alimenter des bases d’entités ou de concepts (qui nécessitent une validation humaine). C’est important dans l’optique de la constitution d’une base d’informations indépendante du corpus des documents, mais, pour le contexte d’un moteur de recherche sur un corpus, le bénéfice ne sera pas immédiat.
Niveau 7 : repérage d’attributs sur les entités et de relations entre les entités
Même chose que le niveau précédent, mais avec des règles plus poussées permettant non seulement de reconnaitre les entités, mais des informations sur ces entités : l’âge d’une personne, la date de sortie d’un film, le poste occupé dans une entreprise, etc. Ici encore, l’intérêt est d’alimenter une base de connaissances. On notera que ces données, s’il s’agit d’entités assez connues, peuvent se récupérer depuis le web sur DBPedia ou Wikidata.
Alors bien sûr, des problématiques à traiter dans la recherche d’information, il y en a d’autres (éventuellement, traitement des logs de recherche des utilisateurs, suggestions de recherche, etc.). J’apprécierai d’ailleurs des pointeurs sur des synthèses de ces problématiques, si vous en avez. Mais ma perspective était ici la réflexion sur le couplage entre un moteur de recherche non-structuré et de la connaissance structurée, par ordre croissant de complexité. Les ontologies, que je n’ai pas décrites dans ces différents niveaux, arrivent encore après, et on est alors bien plus dans des problématiques de constitution d’une base de connaissance (à la Google Knowledge Graph) que des problématique d’accès à un corpus.
Previous Post: Linked Open Data Cloud : nouvelle version

*Très* intéressant/clarifiant. Merci.