

Nous avons développé un outil de test de vocabulaires SKOS…

Clean JSON(-LD) from RDF using Framing
Say you have a nice RDF knowledge graph based on an ontology, or maybe reusing ontologies, and maybe you have specified the structure of the knowledge graph with SHACL. And now you would like to expose your RDF in JSON in an API, for the average developer (or maybe you would like to produce a clean JSON to be indexed by Elastic). And the average developer (or Elastic) does not care about RDF and does not care about the “-LD” in “JSON-LD”, he just cares about JSON; and he is right ! we are here to care about the “-LD” part for him.
So what you need is to produce a clean JSON structure from your raw RDF triples. And when I mean “clean”, I mean :
- no URIs. Nowhere. No URIs in JSON keys, No URIs in types of entities, no URIs in the value of properties controlled by a closed list; the only places where it is acceptable to see a URI are : to give the id of the entities, and when making a reference to such an id of entity within the graph; even in these cases the URIs can be shortened.
- no fancy JSON-LD keys like @type, @value, @datatype, @id, etc.
- indented.
You have 2 possibilities to do that :
- You develop a custom script, to either generate a JSON export of your data, or to implement the API that will query the knowledge graph, parse the triples, and generate that clean JSON output.
- You use JSON-LD framing to automate the production of a clean JSON(-LD) from RDF.
There are 2 nice things about the solution with JSON-LD framing :
- it can be automated
- you automatically retain the RDF compatibility – because your JSON will necessarily be JSON-LD. This means you can import your nice JSON directly in a triplestore.
The principle of JSON-LD framing is that you provide a JSON-LD @context with an additionnal frame specification that defines how the JSON should be structured (indented), which entity to include at each level (entities can be filtered based on some criteria), and also which properties to include in each entity.
To start with JSON-LD framing, what you need is JSON-LD. Any JSON-LD. Typically the raw JSON-LD serialization that any RDF library or triplestore will produce; that kind of ugly, messy, full-of-URIs-and-@language kind of JSON. So something like:

(Brrr, scary, no ?)
And then what you need is the JSON-LD playground with the “Framed” tab. This will allow you to test your context and frame specification.
And when deployed in production, what you will need is a JSON-LD library that is capable of implementing the JSON-LD framing algorithm. Implementations are listed here, and you need an implementation compatible with JSON-LD 1.1.
Example files
As an example, I use a JSON-LD file from the French National Library, the one from Les Misérables here : https://data.bnf.fr/fr/13516296/victor_hugo_les_miserables/ (download link at the bottom of the page).
You can download the initial JSON example, the frame specification, and the result in a zip. The zip also contains intermediate frame specifications.
The @context
We’ll start by specifying the JSON-LD context part.
Map @type to type and @id to id
Average developer will wonder what are those @type and @id keys. Re-map them straight away to type and id:
"type" : "@type",
"id" : "@id",
Schema.org and lot of other specifications do that.
What about @graph ?
If you have a named graph at the top, introduced by @graph, my suggestion would be to simply remap it to a fixed key, like « data », or « entities » :
"data" : "@graph",
Map RDF properties URIs to JSON keys
Get rid of any trace of URI or short URIs in JSON keys. Declare a term for every property in your graph. The simplest way to do this is to use the local part of the URI (after last “#” or “/”) as the term. Order the context by the alphabetical order of the terms. Terms for properties will usually start with a lowercase letter.
In corner cases you may end up with the same term (such as in the example bnf-onto:subject and dcterms:subject), so in that case you need a different key, I chose “bnf-subject” here for bnf-onto:subject and kept “subject” for dcterms:subject.
"creator" : "dcterms:creator",
"date" : "dcterms:date",
"dateOfWork" : "rdagroup1elements:dateOfWork",
"depiction" : "foaf:depiction",
"description" : "dcterms:description",
Map classes URIs to JSON terms
Now you want to do the same thing to get rid of any trace of URIs in the “type” of entities. Declare a term for every class in your ontology/application profile. List the classes in a different section than the properties. Terms for classes will usually start with an uppercase.
"Concept" : "skos:Concept",
"Document" : "foaf:Document",
"ExpositionVirtuelle" : "bnf-onto:ExpositionVirtuelle",
Declare object properties with “@type”: “@id”
Now you want to get rid of all those ugly “id”, we are only interested in listing the values. To do that, modify the mapping of the property (here “depiction”) to state its values are URIs. You need to change the mapping from
"depiction" : "foaf:depiction",
to
"depiction" : { "@value" : "foaf:depiction", "@type":"@id" },
And so parts like this :
"depiction": [
{
"id": "https://gallica.bnf.fr/ark:/12148/btv1b8438568p.thumbnail"
},
{
"id": "https://gallica.bnf.fr/ark:/12148/btv1b9004781d.thumbnail"
},
{
"id": "https://gallica.bnf.fr/ark:/12148/bpt6k5545348q.thumbnail"
}
]
Will be turned into
"depiction": [
"https://gallica.bnf.fr/ark:/12148/btv1b8438568p.thumbnail",
"https://gallica.bnf.fr/ark:/12148/btv1b9004781d.thumbnail",
"https://gallica.bnf.fr/ark:/12148/bpt6k5545348q.thumbnail",
"https://gallica.bnf.fr/ark:/12148/btv1b8438570r.thumbnail"
]
Map datatypes
Now you want to get rid of the @datatype information for literals. If the value of a property always uses the same datatype, which is the case 99,9% of the time, then you can change the mapping from
"property" : "http://myproperty",
to
"property" : { “@id”: "http://myproperty", “@type”:”xsd:date” }
(The example used does not have datatype properties.)
Map languages, with fixed language or when multilingual
Now let’s get rid of the @language. For this you have 2 choices : when the language is always the same for the value, you can indicate it in the context, the same way that you would do for the datatype but with the @language key. So you change from
"description" : "dcterms:description",
to
"description" : { “@id” : "dcterms:description", “@language” : “fr” }
You could even have different terms for different languages, such as :
"title_fr" : { "@id" : "dcterms:title", "@language" : "fr" },
"title_en" : { "@id" : "dcterms:title", "@language" : "en" },
"title" : { "@id" : "dcterms:title" },
or when you have multilingual multiple values, you can make the property a language map by declaring it this way:
"editorialNote" : { "@id" : "skos:editorialNote", "@container" : "@language" },
Which will turn the language code as a key in the JSON output:
"editorialNote": {
"fr": [
"BN Cat. gén. (sous : Hugo, comte Victor-Marie) : Les misérables. - . - BN Cat. gén. 1960-1969 (sous : Hugo, Victor) : idem. - . -",
"Laffont-Bompiani, Oeuvres, 1994. - . - GDEL. - . -"
] },
In that case, watch out for cases where there is a value without language, it will generate a @none key.
Map controlled list values to JSON terms
By now you already get a much cleaner JSON and almost all “unnecessary” URIs have disappeared. But we still have some URI references that we can clean up : the ones that are references to controlled lists with a finite number of values.
We can declare term mappings for those values just like we did to map properties and classes. BUT – and this is the trick, we need to change the property declaration from “@id” to “@vocab” for the replacement to happen. This is documented in the « Type coercion » section of the spec.
In our example, the mapping to languages and subjects are good candidates to be mapped to JSON terms. So we change
"language" : { "@id" : "dcterms:language", "@type":"@id" },
"subject" : { "@id" : "dcterms:subject", "@type":"@id" },
to
"language" : { "@id" : "dcterms:language", "@type":"@vocab" },
"subject" : { "@id" : "dcterms:subject", "@type":"@vocab" },
“fre” : “http://id.loc.gov/vocabulary/iso639-2/fre”,
“eng” : “http://id.loc.gov/vocabulary/iso639-2/eng”,
Shorten remaining URI references
Now the only URIs left are the ids of the main entities in our graph, and references to those ids. Reference to controlled vocabularies with a limited number of values have been mapped to JSON terms. Although we cannot turn all the remaining URIs to JSON terms (because we can’t declare all possible entity URIs in the context), we can shorten them by adding a prefix mapping in the context, in our case:
"ark-https": "https://data.bnf.fr/ark:/12148/",
(I note that there are http:// and https:// URIs in the data, I don’t know why)
The frame specification
So now we have clean values, no URIs, no fancy JSON-LD keys. But we still don’t have a structure indented the way the average developer would expect it; and this is where the frame specification comes into play.
Define indentation and filters (and reverse properties if needed)
The frame specification acts as both a filter/selection mechanism and as a structure definition. At each level you indicate the criterias for the object to be included. In our example we have a skos:Concept (the entry in the library catalog) that is foaf:focus a Work (the Book « in the real world »), and that skos:Concept is the subject of many virtual exhibits. We want to have the Concept and the Work at first level, and under the concept the exhibits. But there is a trick : it is the virtual exhibits that points to the concept with a dcterms:subject, and we want it the other direction : Concept is_subject_of Exhibit, so we need a @reverse property.
To do that, add the following reverse mapping declaration: (don’t modify the existing one):
"subject_of" : { "@reverse" : "dcterms:subject" },
Note the use of « @reverse » to indicate that JSON key is to be interpreted from object to subject when turned into triples.
With that in place, we can write our frame specification, which goes right after the @context we have designed before:
"type" : ["Concept", "Work"],
"subject_of" : {
"type" : "ExpositionVirtuelle"
}
Note how we use the terms defined in the context previously. This is to be understood the following way : « at the first level, take any entity with a type of either Concept or Work, then insert a subject_of key and put inside any value that has a type ExpositionVirtuelle ». This garantees the virtual exhibits objects will go under the Concept, and not above or at the same level. But this is not sufficient, as you will notice if you apply that framing that the Work is repeated under the « focus » property of the Concept, and at the root level. This is because of the default behavior of the JSON-LD playground regarding object embedding (objects are always embeded when they are referenced)
Avoid embedding
To avoid embedding when it is undesired, we can set the « @embed » option to « @never » on the « focus » property, like so :
"type" : ["Concept", "Work"],
"subject_of" : {
"type" : "ExpositionVirtuelle"
},
"focus" : {
"@embed" : "@never",
"@omitDefault": true
}
This tells the framing algorithm to never embed the complete entity inside the focus property, just reference the URI instead.
Also, you will notice the use of « @omitDefault » to true; this tells the framing algorithm to omit the focus property when it has no value. Otherwise, since the Work does not have a foaf:focus property (only the Concept), then it will get a « focus » key set to null.
What about order of keys in the JSON ?
Well, I am sure this can be controlled, either by specifying explicitely all the keys you want, in the order you want them, in the frame specification, or by using an « ordered » parameter to the JSON-LD API, but that is not available in the playground.
If you list all keys explicitely in the frame specification, don’t forget to use wildcards so that any value will match; wildcards are empty objects with « {} »:
"myProperty" : {}
The result
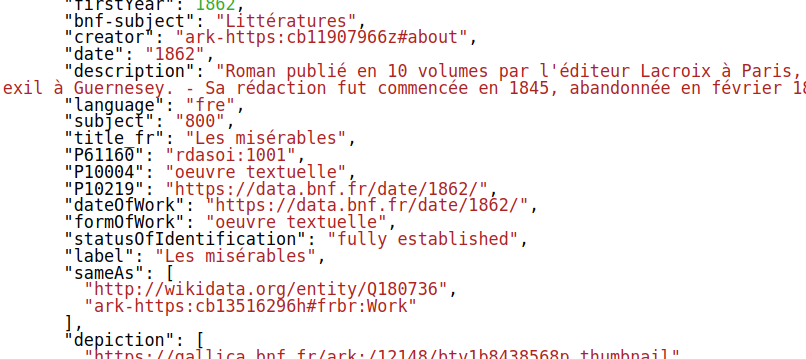
Much nicer no ? This is something you can put into the hand of an average developer.
Automate context generation from SHACL
Do you have a SHACL specification of the structure of your graph ? wouldn’t it be nice to automate the generation of the JSON-LD context from SHACL ? Maybe we could do that in SHACL-Play ? stay tuned !
Probably what we can automate is the context part, which can be global and unique for all your graph, but the framing specification should probably be different for each different API you need; each framing specification will then reference the same context by its URL.
Image : [Encadrement ornemental] ([1er état]) / .Io. MIGon 1544. [Jean Mignon] ; [d’après Le Primatice] https://gallica.bnf.fr/ark:/12148/btv1b53230250h


Salut!
To put forward an alternative view for « No URIs » … if you never expect a consuming application to retrieve the information at the URI, then sure, it can just be an enumerated string value. But if there’s no reason to retrieve the information, does it even need to be a URI ever, or have a URI rather than being a blank node? Is there nothing else about the resource that isn’t in the current document?
Conversely if there’s ever a need to retrieve the representation from the URI, then the consuming application needs to know how to reverse the process to get from the shortened form back to the expanded form. That’s not hard … if you have a JSON-LD aware client, as it could expand the framed, compacted json out into the full form… and then (hopefully) find the URI. Otherwise it would need some understanding of the context document for the expansion. If that uses nested contexts from 1.1, it will be very painful for the consumer.
Three examples:
1. IIIF uses context controlled json terms for vocabulary URIs. The vocabulary is tied explicitly to the JSON-LD in the specification. There’s very little need to ever extend the vocabulary set, and there’s very few occurrences of it as a pattern: https://iiif.io/api/presentation/3.0/#behavior
2. The web annotation data model uses it for motivations: https://www.w3.org/TR/annotation-model/#motivation-and-purpose but otherwise leaves in URIs for targets, sources, and so on as clients definitely need to retrieve them
3. Linked Art never uses it for vocabulary, as the vocabulary entries are very likely to have useful information when you retrieve them. e.g. https://linked.art/model/base/#types-and-classifications
Hope that’s useful to someone
Hi Rob, Thanks for the pointers !
I didn’t mean to replace URIs by strings **in the RDF data**; I meant **presenting** the URIs as strings for the clients. If there is a URI then it is for a reason and we must of course keep it.
What I get from your comment is : if we « hide » URIs behind JSON strings, then a non-JSONLD-aware client can have a hard time knowing it is a URI if it needs to access it; indeed, this could be a reason to leave them as URIs in the JSON.
Does it make sense to create the JSON-LD context from the ontology triples via JSON-LD framing? Without knowing exactly, I‘d assume that the default RDF to JSON-LD generates some generic constructs which could be framed in a common manner.
I had never thought about creating the JSON-LD **context** itself via framing. For the moment I would use a dedicated script that interpret SHACL constraints (rather than OWL ontology) and generates the context. If you happen to do something relating to automated generation of JSON-LD context from OWL or SHACL, let me know !
Very cool. I am also taking a similar approach to create JSON that developers love from RDF. Last week I made a presentation including these ideas, and now I stumbled across your post. Glad to see this approach gaining momentum. If you are interested I can share the video of my presentation.
Please do share !
I recently learned a lot more about the possibilities of JSON-LD, including « @included » flag and language-based or property-based indexes, which really can hide a lot of the RDF complexity from the average JSON developper.
Yes, please share!