
A second usecase Thomas wrote for Veronika Heimsbakk’s SHACL for the Practitioner upcoming…

Le CIDOC-CRM, ne nous arrachons plus les cheveux !
C’est vrai que quand on commence à entendre parler du CIDOC-CRM, il y a de quoi se sentir « Désespéré » (comme le tableau de Courbet); moi aussi, il y a quelques années, si on m’avait demandé de faire quelque chose avec le CIDOC-CRM je me serais arraché les cheveux si je les avais eu encore longs. Mais en fait, ce n’est pas si terrible, et après avoir utilisé ce modèle dans plusieurs projets, je le trouve d’une grande force et d’une grande richesse. Je vous propose plus bas 2 ressources que j’ai mis au point pour des formations sur le CIDOC-CRM : une navigation visuelle dans les classes du CRM+FRBRoo, et un début de tutorial SPARQL sur les données du British Museum.
Le CIDOC-CRM est une ontologie formelle de haut-niveau permettant de structurer la description et l’histoire d’objets patrimoniaux (tableaux, sculptures, bâtiments, fouilles archéologiques, etc.) – ou d’autres informations similaires. L’objectif de ce modèle est de permettre l’intégration de données provenant de sources hétérogènes dans un graphe commun, cohérent, à l’échelle d’une institution ou au-delà, permettant ainsi l’accès et l’interprétation scientifique de ces informations.
Le périmètre du CRM, tel qu’il est défini, est « toutes les informations requises pour l’échange et l’intégration de données scientifiques à propos du passé humain et de toutes les preuves de ce passé arrivées jusqu’à nous ». Etant fait pour la description structurée de l’histoire d’objets patrimoniaux, le CRM utilise a plein une modélisation évènementielle; c’est-à-dire que fondamentalement, on ne dit pas « Le tableau Le Désespéré a pour date de création : [entre 1843 et 1845] », mais « Entre 1843 et 1845, Gustave Courbet a conduit une Activité de Création dont l’objet était le tableau Le désespéré« ; nuance. D’ailleurs, si j’en crois la notice Wikipedia, on ne dit pas non plus « ce tableau a pour titre Le Désespéré« ; on dit « Gustave Courbet a effectué une activité de nommage de ce tableau qu’il a baptisé Désespoir« , puis « Quelqu’un d’autre (qui ?) a (probablement) effectué une autre activité de nommage (quand ?) et a baptisé le même tableau Le Désespéré« .
Ce qui fait la force du CIDOC-CRM…
Le CIDOC-CRM est un modèle issu de plus de vingt ans de standardisation au sein du Comité International pour la Documentation (CIDOC) du Conseil International des Musées. Autant dire qu’il est le résultat d’une sédimentation de longues réflexions, ce qui rend ses fondations théoriques extrêmement solides. Le CRM a fait l’objet de 2 versions d’un standard ISO, ISO21127:2004 et ISO21127:2014. Il donne donc un cadre de modélisation rigoureux, mais avec une logique qu’il faut s’approprier.
Son paradigme de modélisation événementielle est très puissant et permet d’exprimer de nombreuses informations de façon très flexible. Les Evènements (ou plutôt, les Activités) sont les objets centraux que l’on décrit à l’aide du CIDOC-CRM : des Acteurs participent à des Evenements, qui se produisent dans un Lieu donné, une Temporalité donnée, et affectent des Objets donnés; tout cela pouvant être nommé avec des Appellations et typer avec des Types. Voilà, en une phrase, vous savez tout !
Le CIDOC-CRM est un modèle générique avec un fort niveau d’abstraction, et il ne descend volontairement pas dans le détail de spécifications de certains domaines métier particulier; c’est pourquoi il a fait l’objet d’extensions pour des domaines spécifiques. Dans le monde de l’infodoc on citera en particulier FRBRoo, l’intégration des principes du FRBR dans le cadre de la modélisation orientée objet du CIDOC-CRM, ou bien PRESSoo, lui-même une extension de FRBRoo pour la carctérisation des publication en série; dans d’autres domaines, on peut citer CRMarchaeo, une extension pour la description des données archéologiques, une communauté active autour du CIDOC-CRM.
…Et ce qui le rend compliqué
Ce n’est pas la taille de ce modèle qui le rend compliqué. Le CIDOC-CRM contient 84 classes et 154 propriétés (288 si on compte aussi les inverses) (chiffre approximatif). C’est peu, si l’on compare aux 602 classes et 877 propriétés de schema.org, et cela en fait une ontologie de taille moyenne.
Franchement, la chose qui le rend le plus compliqué, c’est peut-être sa documentation. Un sympathique fichier PDF de 115 pages (tiens, une nouvelle version sort aujourd’hui 26 mars 2019, un hasard), ça c’est sûr, c’est de la spécification formelle ! de bon vieux tableaux de propriétés à la schema.org pourraient être les bienvenus. MAIS MAIS mais, pour vous aider à vous plonger dans le CIDOC, voici une petite visualisation de l’arborescence des classes du modèle et de FRBRoo, construite à partir de SKOS-Play :
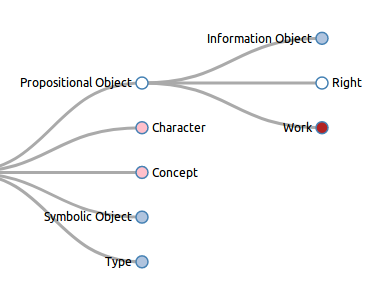
Par ailleurs, les diagrammes fournis pour les uses-cases, assez utiles, utilisent un formalisme auquel on n’est pas habitué dans la modélisation d’ontologies classiques. Pour d’autres documents d’introduction on pourra consulter avec profit la présentation du CRM et de FRBRoo sur le site de Doremus.
Un des autres aspects qui le rend compliqué c’est son fort niveau d’abstraction. Le CRM définit en effet des notions comme « Persistent Item », « Man-Made Thing », « Propositional Object »… pas évident de s’approprier la définition de ces notions. Ajoutez à cela que tous les identifiants du CRM commencent par un code : « E5_Event », « E70_Thing », « P94_has_created », et la lecture devient compliquée. Cette identification, rebutante au premier abord, n’est finalement pas pire qu’une autre, d’autant que les noms des propriétés et des classes sont associés à des définitions très précises, et on fini par connaître par coeur les plus importants (E55_Type, P14_carried_out_by…).
Par ailleurs le CRM est formellement défini dans le PDF de référence sus-mentionné, et il n’existe pas d’implémentations de référence du modèle en OWL. Les implémentations OWL fournies sur le site sont explictement non-officielles, et de toutes façons pas à jour. L’implémentation OWL la plus à jour (mais qui date tout de même d’il y a 2 ans, et de 3 versions du modèle) semble être celle d’Erlangen-CRM. Ce n’est donc pas forcément immédiat d’intégrer ce modèle dans une application basée sur les technologies du web de données.
Les projets qui utilisent le CIDOC-CRM
Mais qui qui qui (sont les snorkis) se sert du CIDOC-CRM ? L’implémentation la plus impressionnante est celle du British Museum, notamment au travers de l’interface ResearchSpace. Vous aimez les spaghettis ? voici la formalisation des données du catalogue du BM en CIDOC-CRM :

Vous voulez expérimenter avec les données CIDOC-CRM du BM ? je vous propose un tutorial d’interrogation des données du British Museum en SPARQL.
Aux Etats-Unis, le Yale Center for British Art publie également des données dans le CIDOC-CRM, mais semble-t-il assez light.
Le projet Doremus a créé une extension de FRBRoo / CIDOC-CRM pour la musique classique (composition, concerts), documentée ici.
Je travaille en ce moment sur une première version de la plateforme OpenArchaeo pour l’intégration de données de fouilles archéologiques, alignées sur le CIDOC-CRM à partir de base relationnelles (base ARSOL) et de fichiers XML (base AERBA).
Par ailleurs, dans le cadre de ELI (European Legislation Identifier), j’ai spécifié l’extension du modèle ELI pour la description des étapes et des documents lors de l’élaboration des projets de lois : ELI-DL (pour « draft legislation »); c’est un bon cas pour l’utilisation du CIDOC-CRM et de FRBRoo, puisque l’élaboration d’une loi est vue comme une séquence d’Activités utilisant ou produisant des documents, jusqu’à la publication finale de la loi au JO. C’est également un bon scenario d’utilisation du CIDOC-CRM comme cadre méthodologique, tout en utilisant uniquement des propriétés métier pour masquer les notions trop abstraites du CRM.
On peut également supposer que l’Institut National d’Histoire de l’Art (INHA) s’intéresse à ce genre de sujet. Le laboratoire LARHRA, laboratoire de recherche historique à Lyon, s’y intéresse également dans le cadre du projet SYMOGIH, pour lequel un autre modèle de données avait été initialement mis au point.
Les outils pour convertir
Le CIDOC-CRM étant un modèle fait pour l’intégration de données, le labo de FORTH, en Crète, qui abrite les cerveaux du CRM, a mis au point un language et un outil de mapping, X3ML, permettant de mapper et convertir des fichiers XML vers le modèle CIDOC-CRM. Pour convertir les données de bases relationnelles, on peut utiliser –Ontop–.
Alors, près à vous frotter au CIDOC-CRM ? avec toutes ces infos au moins, vous ne vous arracherez pas les cheveux !

Thomas, thanks for the great article, was wondering if you could share how you created the D3 tree for CIDOC-CRM, as this is a very simple way to interact with the data, but also understand the depth of the hierarchy
Hello – the CIDOC-CRM tree hierarchy is built from the FRBRoo RDFS implementation available from http://www.cidoc-crm.org/frbroo/fm_releases, using SKOS-Play at http://labs.sparna.fr/skos-play/upload?lang=en, and checking « Transform your OWL ontology into SKOS ». The file is then manually post-processed to add the color differences, depending on the node namespace.
Bonjour,
Merci pour ce post. Plusieurs remarques :
Le Labex les passés dans le présent à utiliser le CIDOC-CRM et à publier sur les projets.
Le projet American Art Collaborative (http://americanartcollaborative.org/) a aussi utiliser le CIDOC et publér un rapport un intéressant sur les gains et difficultés d’utiliser ce standard.
The Yale Center for British Art n’est pas situé en Grande Bretagne mais aux USA » The Yale Center for British Art is a public art museum and research institute that houses the largest collection of British art outside the United Kingdom »
Cordialement
Merci Jean-Luc
Y a-t-il des liens vers les données en CIDOC-CRM des projets du Labex « Les passés dans le présent » ?*
Je corrige l’erreur sur Yale… merci
Thomas
Bonjour Thomas,
Désolé de ma réponse un peu tardive mais confinement oblige…
quelques liens :
https://www.cairn.info/revue-document-numerique-2018-1-page-37.htm
http://passes-present.eu/fr/modelisation-referentiels-et-culture-numerique-319
https://halshs.archives-ouvertes.fr/halshs-01547462/document
et un article à paraitre dans la revue Cultures et musées en juin 2020
Porte toi bien
Jean-Luc