
Le développement de l'industrie informatique se réduisait à ses débuts…
UNESCO Thesaurus published with Semantic Web standards and Open-Source software
Sparna conducted in 2016 the replacement of the Thesaurus Management Software and thesaurus publication platform for the UNESCO, with Open-Source tools all relying on Semantic Web technologies. The result is the new UNESCO vocabularies publication platform at http://vocabularies.unesco.org. The project was conducted in 2 phases : a new thesaurus publication platform based on Skosmos, SKOS Play and Fuseki, and in a second phase the deployment of VocBench as the new Thesaurus Management Software. The system leverages Semantic Web standards by relying on SKOS as the data exchange format, SPARQL as the online thesaurus query language, and dereferancable URI identifiers.
The new thesaurus browser
The first objective was to replace the thesaurus publication platform, while maintaining existing backoffice tools for thesaurus management. This choice allowed to quickly demonstrate a publicly available interface for searching and browsing the vocabulary, without waiting for the deployment of the complete system.
Skosmos was used as the thesaurus browser; it is easy to deploy, well documented, and the team behind it from the National Library of Finland is super-reactive for fixing bugs. It offers out-of-box features like alphabetical/hierarchical browsing, autocomplete search, URI-based content negociation, and a feedback form. Important aspects for UNESCO were the ability to have a multilingual interface (English, French, Spanish, Russian), the possibility to customize the stylesheets/logo/help page, or the order of the fields in a concept display page. We added a direct link to trigger a search in the UNESDOC database from a concept page in Skosmos, thus easily linking the new thesaurus browser to the existing resource center.
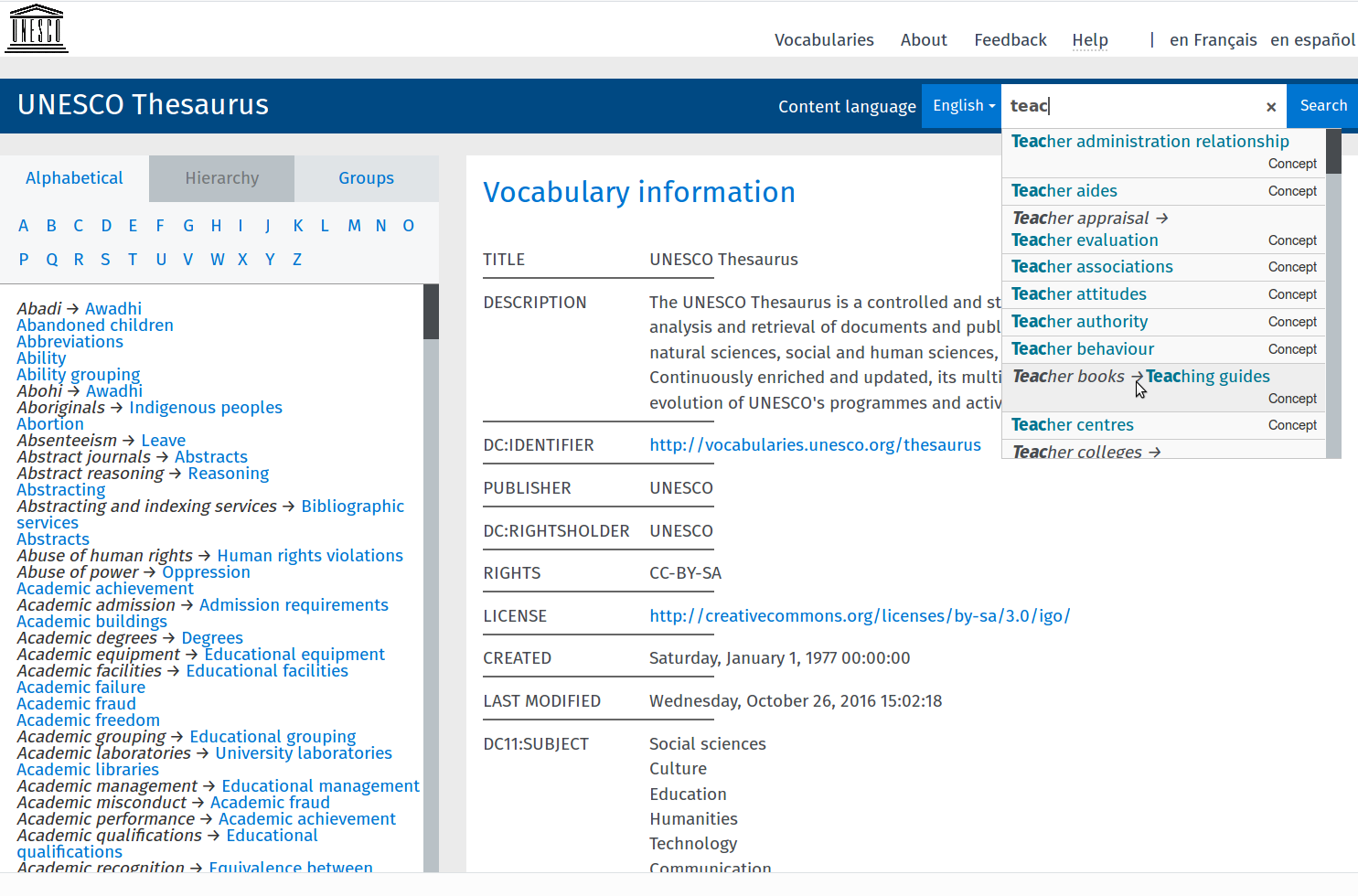
UNESCO thesaurus published in Skosmos
2 additionnal components were used for a complete vocabulary publishing solution; SKOS Play was used to generate downloadable PDF documents generated from the SKOS thesaurus : complete editions of the thesaurus with alphabetical index, hierarchical tree and translation tables, and KWIC indexes, each in French, English, Spanish and Russian. The documents are regenerated automatically each time a new version of the thesaurus is published. Fuseki with a customized SPARLQ form is used as the frontend for public SPARQL querying of the thesaurus.
Meron Ewketu, responsible for the UNESCO thesaurus, describes the benefits of the new publication platform : « The obvious benefit is the enhanced user interface : a nice hierarchical display, a powerful search, an easy navigation between the different language versions. Thanks to these features the platform was immediately endorsed by our user community. What is also very much appreciated is the possibility of responding to various user needs in terms of format and content. Being able to extract part of the thesaurus as per our users’ requirements, and being able to deliver the content in a variety of formats, including PDF, using the SPARQL endpoint and SKOS Play. We have also noticed an increase in user participation. The feedback form enabled us to engage with our users more easily.«
The Collaborative Thesaurus Management Software
The second phase of the project aimed at replacing the old thesaurus management software, and integrating it with the new thesaurus browser. UNESCO and Sparna chose to deploy VocBench, an open-source SKOS-based thesaurus management solution from the Tor Vergata University in Rome. We also considered Ginco as a possible alternative; VocBench was chosen mainly for its ability to properly handle collaborative multi-user maintenance of the thesaurus; this was an important aspect for UNESCO, having remote contributors to the thesaurus in Russia, and translations in Chinese and Arabic coming in the future; the ability to work remotely and to have a validation workflow of the modifications was essential. In addition, Vocbench is already deployed by other international organizations, and the upcoming v3 of Vocbench is funded by the ISA2 program of the European Union, thus giving garantees as to the maintenance of the application in the next few years.
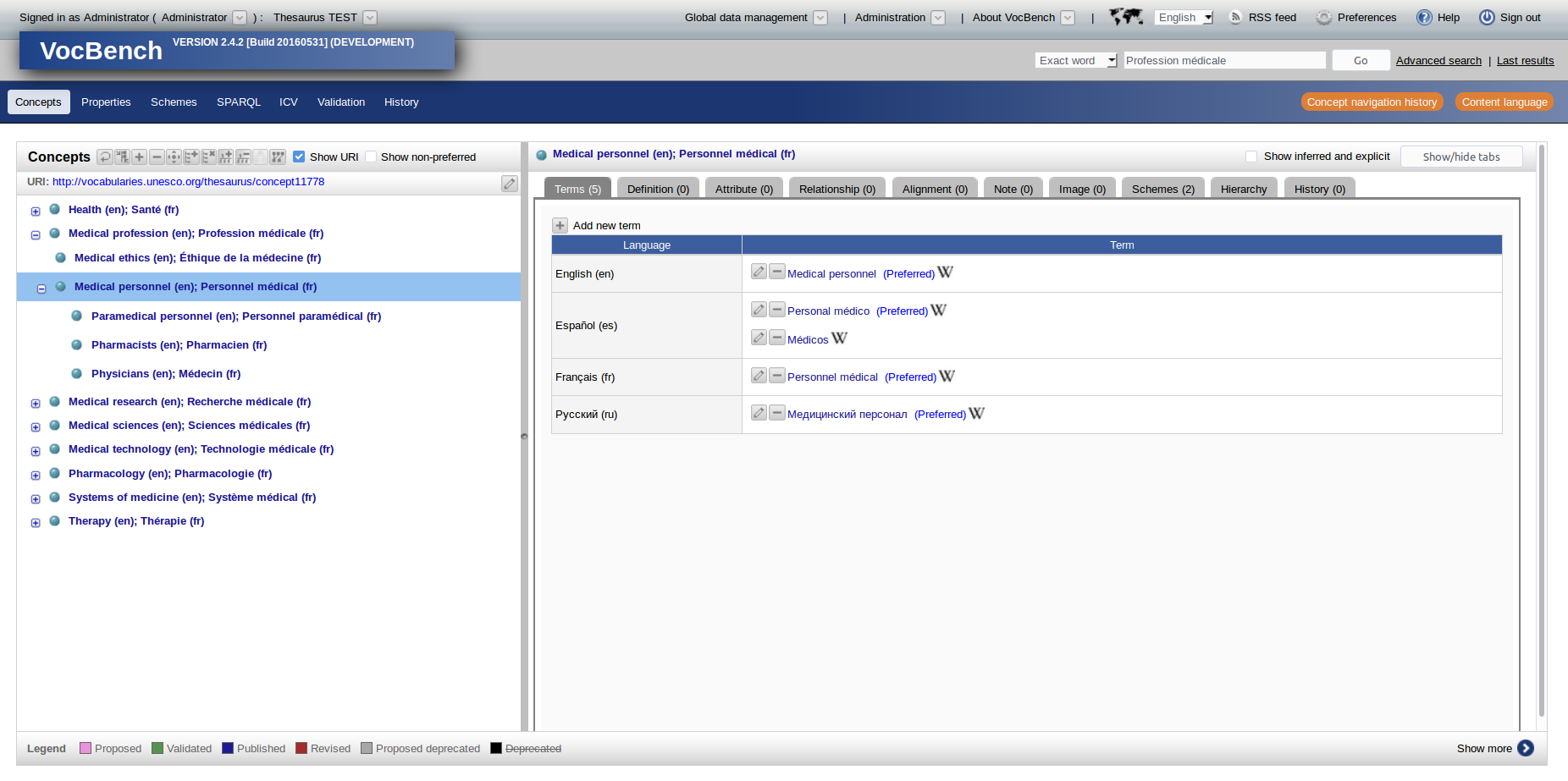
UNESCO Thesaurus managed in VocBench
VocBench is SKOS-XL from the bottom up and stores the thesaurus data in an RDF triplestore. We chose to deploy GraphDB from Ontotext as the backend for VocBench. VocBench offers user profile management and edition workflow management, multilingual thesaurus editing, and the possibility to add custom attributes to the thesaurus concepts and terms. We used this to capture corresponding country codes and language codes for certain concepts in the UNESCO thesaurus with a small UNESCO vocabulary publishing ontology describing these 2 properties.
The deployment in production of Vocbench is fairly complex, essentially due to the middleware component on which it relies, called SemanticTurkey; VocBench requires a total of 4 pieces of software (relationnal database, RDF triplestore, SemanticTurkey server, VocBench application server). But, once you are familiar with the procedure, and again with the precious help of the community on th mailing-list, everything works fine. Another limitation of VocBench v2 is that it does not support SKOS Collections, only ConceptSchemes.
Ms Ewketu explains the benefits of VocBench : « Apart from the obvious functionalities of collaborative and distributed maintenance, other important aspects for us were the ability to manage several vocabularies and the ability to make alignments with other thesauri. Being able to document changes through history notes is something very interesting, which I am sure we will exploit in the future. This is quite interesting for researchers who study the evolution of terminology, within an organization.«
« leverage the thesaurus to achieve interoperability«
The project clearly is a success story for Semantic Web technologies : with URIs, RDF and SKOS as W3C standards, the UNESCO has achieved its mission of transforming its thesaurus into open, reusable data. The thesaurus is now available for browsing by humans and in machine-readable formats. URIs makes it open for linking from/to other knowledge organization systems on the web, thus enabling interoperability between document databases of multiple organizations.
The project is also a great success story for Open Source; the support from the community and the maintainers of both Skosmos and VocBench was essential for such a quality achievement, and Sparna and UNESCO contributed to both communities by providing translations, filing bug reports and testing new versions. It shows how these tools have enabled the UNESCO to replace an entire thesaurus management platform with no licensing cost, no vendor or data lock-in.
« The main benefit of this project for us will be to leverage the thesaurus to achieve interoperability between our different repositories, as well as with external datasets. » concludes Ms Ewketu from UNESCO. « We are currently working on integrating the new thesaurus within the various information systems. Next phase will be mapping our thesaurus with vocabularies such as the UN Thesaurus and Eurovoc. »
Want to learn more ? reach me at thomas /dot/ francart /at/ sparna /dot/ fr.



Bonjour Thomas,
Merci de ce retour.
Dis moi : l’onglet hiérarchie n’a pas l’air de fonctionner et le message qui s’affiche ( « impossible d’afficher les concepts racines de la hiérarchie pour ce vocabulaire ») m’interpelle : ces relations sont bien intégrées au thésaurus de l’unesco. Une raison particulière ? .
Merci d’avance. Sylvie
(french below)
The « Hierarchy » tab on the left is activated once you click on a concept entry. It is not activated when no concept is selected, since the thesaurus is organized in domains/microthesauri, so displaying the full concepts hierarchy, not organized by domains, does not make a lot of sense.
L’onglet « Hiérarchie » sur la gauche s’active lorsqu’on a cliqué sur une entrée de concept. Il n’est pas actif par défaut quand aucun concept n’est sélectionné, puisque le thesaurus est subdivisé en domaines/micro-thesaurus; montrer la hiérarchie complète des concepts, sans l’organiser par domaines, n’aurait pas grand intérêt.
Hello, was wondering if you have seen any documentation around Apache Jena Fuseki working with VocBench? As we are bit challenge at the moment getting them to ‘talk’ to each other..
Hi Phil
I don’t have personal experience on Fuseki+VocBench. You should ask the question on the VocBench users mailing-list (https://groups.google.com/forum/#!forum/vocbench-user), that’s the best place to get an answer.
Having your feedback on this kind of configuration would be valuable for the community, I guess.
Cheers
BTW : is it required for you to use Fuseki as a triplestore ? VocBench is tested on GraphDB, which is (in my opinion) a good triplestore, with nice admin interfaces, so you could also give it a try.
Hi Thomas,
I am interested in running a similar setup.
After a couple of years of using the current stack of technologies, mainly VocBench and Skosmos, have you guys made any architectural changes to your infrastructure?
Also, your article does not mention which triplestore you are using for Skosmos. In Skosmos’ installation, they recommend Apache Jena + Fuseki. I am guessing here that you guys are using the same GraphDB because of your VocBench instance right? My understanding is that Skosmos is just the browser view of the SKOS data and so it should be the slave to the point-of-truth, which is the SKOS data entered into using VocBench, in GraphDB.
I look forward to your responses.
Thanks,
Edmond
Hello Edmond
UNESCO still runs happily the same stack of technologies.
Skosmos uses Jena+Fuseki, and Vocbench uses GraphDB; there are 2 disconnected triplestores, and a clear backoffice/frontoffice separation, for multiple reasons : security, performance, and mostly business process : publishing a new thesaurus version from Vocbench to Skosmos is an action triggered by the thesaurus admin once the thesaurus has reached a stable state; ongoing modifications to the thesaurus in Vocbench are not visible before the data is published and pushed to Jena. Also, this publication process does some filtering on the SKOS data (mostly filter unvalidated concepts/terms, and, if I remember correctly, turning SKOS-XL in SKOS, as the Skosmos version used did not handle SKOS-XL at that time).
I have deployed Skosmos with a slightly different architecture at http://data.legilux.public.lu/vocabulaires, where it is connected to a Virtuoso triplestore that is the central point of data dissemination for the Luxemburgish legislative data (including main legislation portal http://legilux.public.lu/).
Cheers