Je publie la traduction française de la recommendation SKOS. SKOS…
Linked Open Data Cloud : nouvelle version
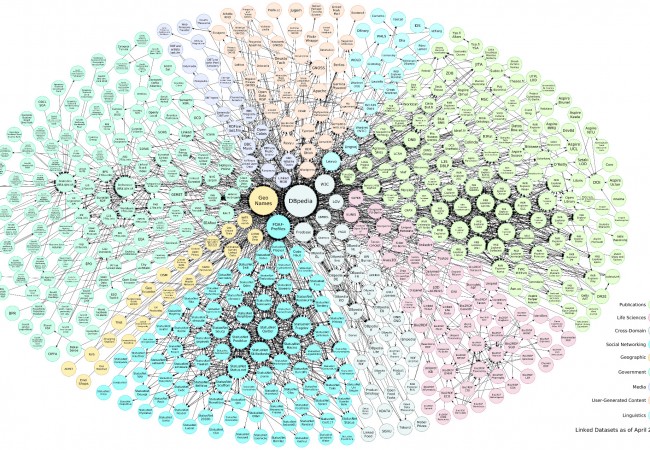
Beaucoup de discours de présentation sur le web de données utilisent l’image du « Linked Open Data Cloud« , le nuage des données liées, pour illustrer la notion de publication de données sur le web, et celle de liens entre les jeux de données. Ce visuel illustre chaque dataset par un cercle (coloré) et indique les liens entre dataset par des flèches. Certains montrent l’évolution de ce « nuage » dans le temps, pour illustrer la croissance de la quantité de données liées disponibles, et dire que « vite, dépêchez-vous, il y a plein de données à réutiliser et _vous aussi_, vous pourriez faire partie de ce nuage en publiant vos données ». Le problème est que cette image de nuage de données étaient un peu passée car la dernière version datait de septembre 2011… La bonne nouvelle c’est que l’image vient d’être remise au goût du jour (par Chris Bizer et son équipe de l’Universität Mannheim en Allemagne), presque 3 ans après sa dernière mouture. Et ça se passe ici.
Il faut toujours prendre un peu de recul et se méfier de la propagation des discours qui ne sont pas toujours fondés : ce visuel présente un certain danger de réduction de la problématique du partage de données structurées sur le web, d’abord parce que d’autres données liées sont disponibles que celles représentées par cette image (ne pas prendre ce diagramme comme un point d’entrée si vous cherchez des données), ensuite parce que cette image a tendance à masquer les problématiques bien différentes qui se cachent derrière ces données (mise en ligne de bases de données déjà structurées, utilisation de données crowdsourcées, traitement automatique du langage, retraitement de formats semi-structurés, aggrégations de plusieurs bases, etc.), ensuite encore parce qu’il ne dit rien de la qualité des données publiées, finalement parce que les données structurées sur le web, c’est aussi l’open data ou la structuration des contenus (RDFa, schema.org). Mais cette image reste un excellent support de communication pour introduire la problématique.
Bon, et sinon, si on regarde d’un peu plus près cette image, qu’y voit-on ?
- D’abord (mais ça ne se voit pas), la détection des données est faite à la fois à partir des données référencés dans l’annuaire datahub.io (tag lod) et (c’est nouveau) à partir d’un crawl automatique des données du web datant d’avril 2014;
- Il y a plus de jeux de données : 520 contre 337 dans la version précédente; et 2900 liens entre jeux de données;
- La taille des cercles n’est plus proportionnelle à la quantité de données, mais aux nombres de liens entrants. Ce n’est pas la taille qui compte (!), mais, dans ce monde en réseau, le nombre de données qui référencent les vôtres;
- Geonames occupe une place (presque) aussi centrale que DBPedia;
- Il y a un nouveau code couleur pour les datasets relatifs à la linguistique;
- On y trouve maintenant les déclinaisons linguistiques de DBPedia, comme le DBPedia francophone;
Et si l’image a été remise à jour, le message qui l’accompagne dans les présentations devrait lui-aussi subir un petit lifting, et c’est intéressant de lire ce que réponds Chris Bizer là-dessus notamment en comparant les données liées et les contenus structurés (Microdata/RDFa/Microformats) :
- Les sites qui mettent à disposition des données structurées sous forme de Microdata/RDFa/Microformats sont 1000 fois plus nombreux (« three order of magnitude larger ») que ceux publiant de la données liée;
- Les données liées et les données disponibles via Microdata/RDFa/Microformats ne couvrent pas les mêmes domaines : e-gouvernment, bibliothèques, sciences de la vie, linguistiques, géographie pour les premières, et produits, commentaires utilisateur, adresses, événements, offres d’emploi, recettes, personnes pour les secondes. Peu de recouvrement entre les 2 technologies en terme de données;
- dans le monde Microdata/RDFa/Microformats, on ne trouve pas, ou très peu, de liens vers d’autres données, là où on en trouve dans le monde des données liées, jusqu’à un certain point (normal, c’est fait pour ça); et la présence de liens, notamment vers des référentiels terminologiques partagés, peut favoriser la réutilisation des données;
- Les données que l’on trouve dans les données liées sont très structurées, celles que l’on trouve en Microdata/RDFa/Microformats ne vont en général pas plus loin que 3 ou 4 attributs, contenant en général du texte;
Et de conclure : « Les données liées ont donc été adoptées par des communautés qui ont un intérêt à voir leurs données facilement réutilisées et sont prêtes à en faire l’effort, comme les bibliothèques, les gouvernements, le monde de la recherche (avec en tête les sciences du vivant et la linguistique qui ont adopté en premier ces technologies) et les réseaux sociaux. Et il est aussi logique de voir que d’autres communautés adoptent Microdata/RDFa/Microformats, celles qui veulent principalement pousser leurs données vers les applications Google pour avoir plus de trafic sur leur site et qui n’ont pas d’intérêt à créer des liens [dans leurs données] vers d’autres (qui sont probablement de toutes façons leurs concurrents) ».
Alors, en caricaturant, les données liées pour le public, Microdata/RDFa/Microformats pour le privé ? on n’est pas si loin de la vérité, sans doute.