

Dans le billet précédent nous avons vu comment Talend pouvait…
Générer du RDF avec Talend (un tutorial)
Talend Open Studio est un outil d’ETL, open-source et avec une version gratuite, utilisé pour récupérer des données d’une ou plusieurs bases, ou flux, les transformer, et alimenter d’autres bases, ou générer des rapports.
On le rencontre parfois en lien avec des projets de graphes de connaissances RDF, sans toutefois l’avoir jamais réellement mis en œuvre. Nous vous proposons ici d’explorer comment Talend peut être utilisé pour convertir des données CSV en RDF (RDF/XML plus précisément), tout cela uniquement avec des composants graphiques et sans écrire de code. C’est là un des gros avantages de l’approche : l’agencement de composants graphiques, de façon (relativement) simple, permet le paramétrage de jobs de conversion par des profils qui ne sont pas des développeurs.
Le code source du Job Talend pour produire du RDF que nous vous proposons de suivre ici peut être téléchargé depuis ce repository Github pour être importé dans Talend.
Les projets de mise en place de graphes de connaissances nécessitent en effet invariablement de la conversion de données vers du RDF pour alimenter le graphe. Ces conversions peuvent être faites :
- de façon massive et une seule fois (reprise intégrale d’une source de données pour basculer dans le graphe)
- de façon massive et répétées plusieurs fois (synchronisation périodique d’une source de données avec le graphe, pour maintenir les deux en synchro, mais sans temps réel)
- de façon unitaire au fil de l’eau (synchronisation des enregistrements un par un, à chaque modification dans les données source, pour maintenir les données source et le graphe synchronisés en temps réel ou quasi temps-réel)
Il y a de nombreuses techniques de conversion des données source pour alimenter le graphe, on citera :
- les feuilles de style XSLT pour traiter du XML (pour moi la “voie royale”), à l’expressivité quasi sans limite et aux performances excellentes (technique utilisée dans le développement du convertisseur Records in Context par exemple);
- L’ajout d’entêtes de @context JSON-LD sur des flux JSON, pour que le flux JSON soit interprétable directement comme du RDF;
- L’écriture de scripts custom, bien sûr, Python, Java, etc.
- L’utilisation d’outils de mapping de base relationnelles basés sur R2RML comme OnTop;
- L’utilisation de la nouvelle interface de mapping RDF de GraphDB, comme une extension d’OpenRefine (il faudra qu’on en reparle);
- L’utilisation du convertisseur Excel vers RDF de SKOS Play, lorsque les données source sont saisies à la main dans des tableurs (on fait plein de choses avec ça, y compris créer des règles SHACL);
Et donc, en plus de tout cela, nous pouvons maintenant ajouter Talend à la panoplie des techniques possibles de production de graphes RDF !
Installez Talend et paramétrez un Job avec 3 composants
Pour suivre l’exemple de job de conversion proposé ici, téléchargez et installez Talend Open Studio For Data Integration.
Le job d’exemple que nous allons paramétrer utilise les composants suivants :
- Un composant tFixedFlowInput pour lire (ici, générer) les données d’entrée.
- Un composant tMap pour transformer les données et en particulier générer tout ce qui est nécessaire pour produire le RDF, en particulier les URIs des sujets et des objets.
- Un composant tAdvancedFileOutputXML pour créer le fichier RDF/XML de sortie.

Créez un nouveau Job Talend, et à partir de la palette de composants sur la droite de l’écran, ajoutez les 3 composants dans votre job.
Configurer les données d’entrée
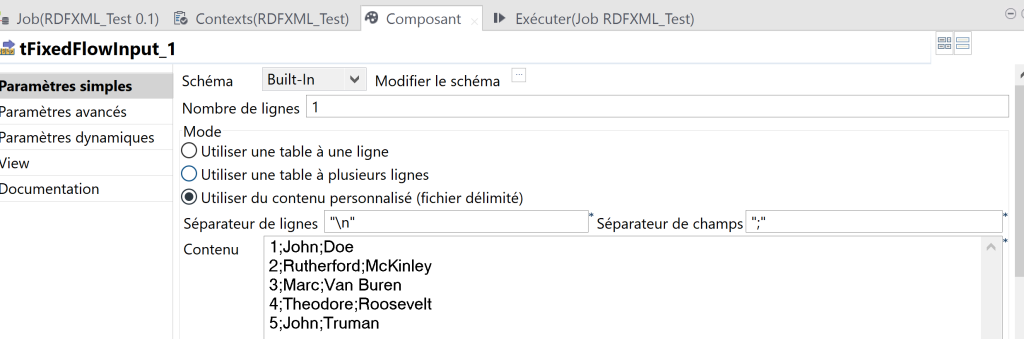
Nous allons configurer des données d’entrée d’exemple, type CSV, avec 3 colonnes qui décrivent des personnes : ID, Prénom et Nom.
- Dans l’espace de travail, sélectionnez le tFixedFlowInput_1 .
- Cliquez sur la vue Component pour paramétrer ses propriétés de base dans l’onglet Basic settings.
- Cliquez sur le bouton […] à côté du champ Edit Schema pour décrire la structure des données que vous souhaitez à partir des variables internes. Dans ce scénario, le schéma est constitué de trois colonnes : ID, first et last, toutes de type String.
- Cliquez sur OK pour fermer la boîte de dialogue.
- Dans les propriétés Basic settings du composant tFixedFlowInput 1 sélectionnez “Use Inline Content (delimited file)”. Dans le champ contenu, ajoutez les informations:
1;John;Doe
2;Rutherford;McKinley
3;Marc;Van Buren
4;Theodore;Roosevelt
5;John;Truman
- Connectez le composant tFixedFlowInput_1 au tMAP_1 avec le bouton gauche de la souris. Choisir l’option Row > Main et connectez au composant tMAP.

Mapper les données pour générer des URIs (et le reste)
La seconde étape consiste à produire tout ce dont on a besoin pour générer le RDF, en particulier générer les URI des ressources. Nous allons donc générer une URI pour chaque personne à partir de son ID.
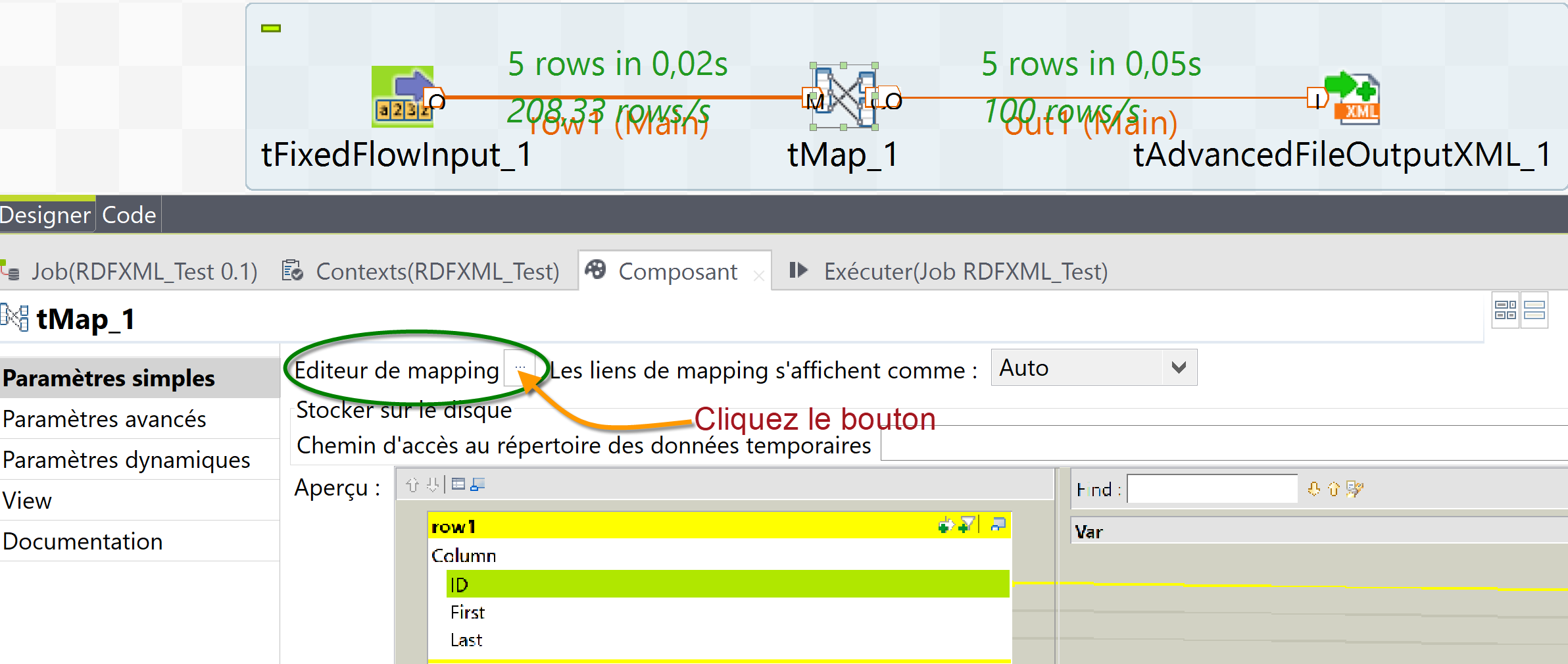
- Configurez le composant tMAP_1.
- Éditez le composant avec l’option éditeur de mapping. Cette option ouvrira une fenêtre séparée.
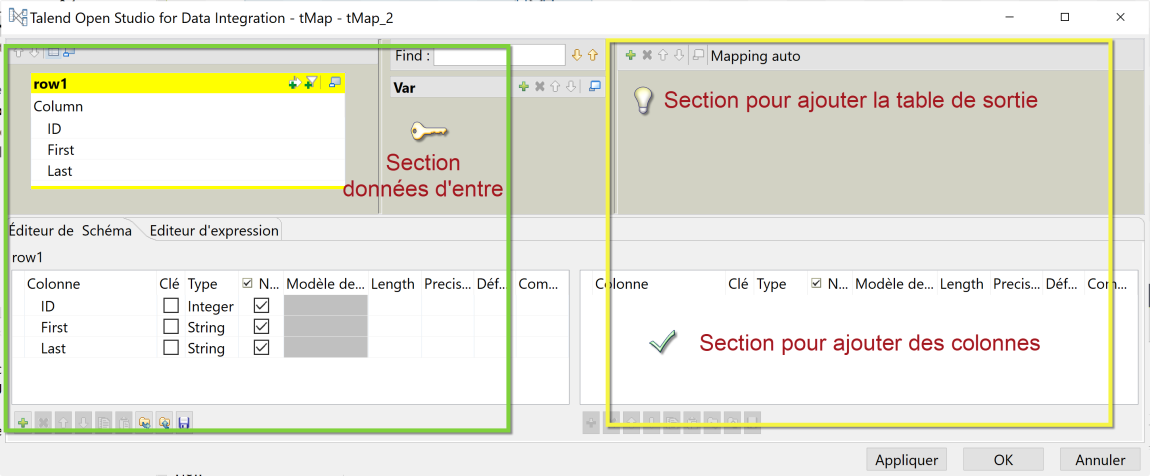
- Ajoutez une table de sortie avec le bouton plus [+] et donner un nom : out1.
- Ajoutez les colonnes dans la section correspondante comme affiché dans l’image ci-dessous : en sortie nous allons produire une colonne “URI” à la place de “ID”, et les colonnes “First” et “Last” restent les même.
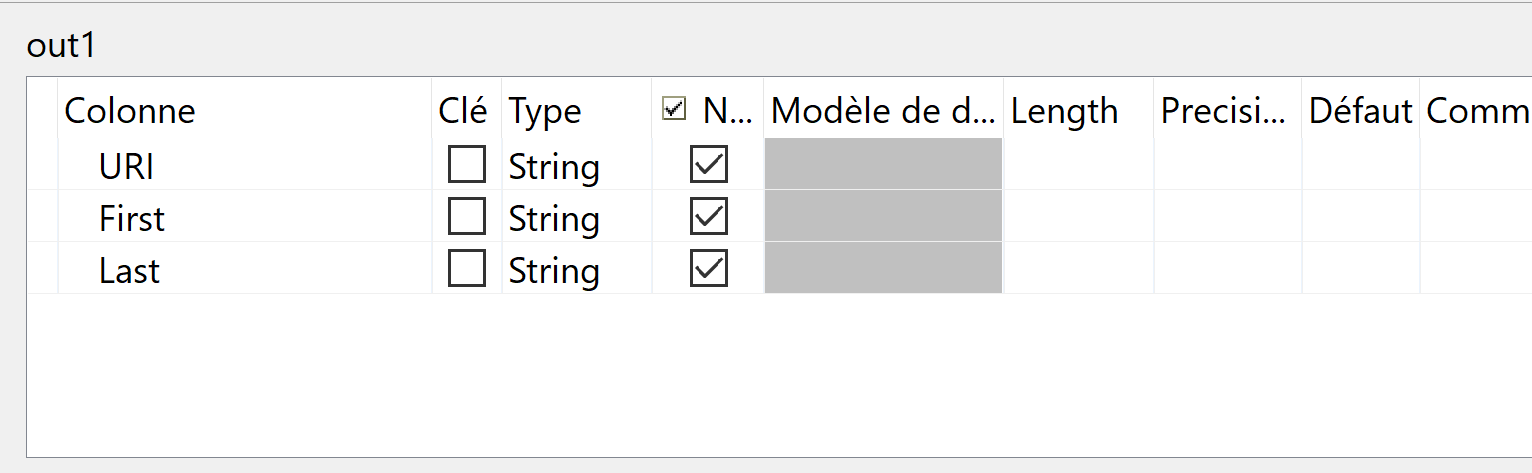
- Glissez chaque colonne d’entrée à la table de sortie :
- First va sur First
- Last va sur Last
- et ID va vers URI
- Nous allons transformer la colonne ID pour générer l’URI, en utilisant une expression de concaténation « http://sparna.fr/dataset/persons/person_ »+row1.ID.toString(). Pour cela, dans le champs “Expression” de la colonne “URI, copiez/collez l’expression de concaténation « http://sparna.fr/dataset/persons/person_ »+row1.ID.toString(). Vous pouvez également cliquer sur le bouton “constructeur d’expression” pour ouvrir une fenêtre dédiée où vous pourrez saisir l’expression.
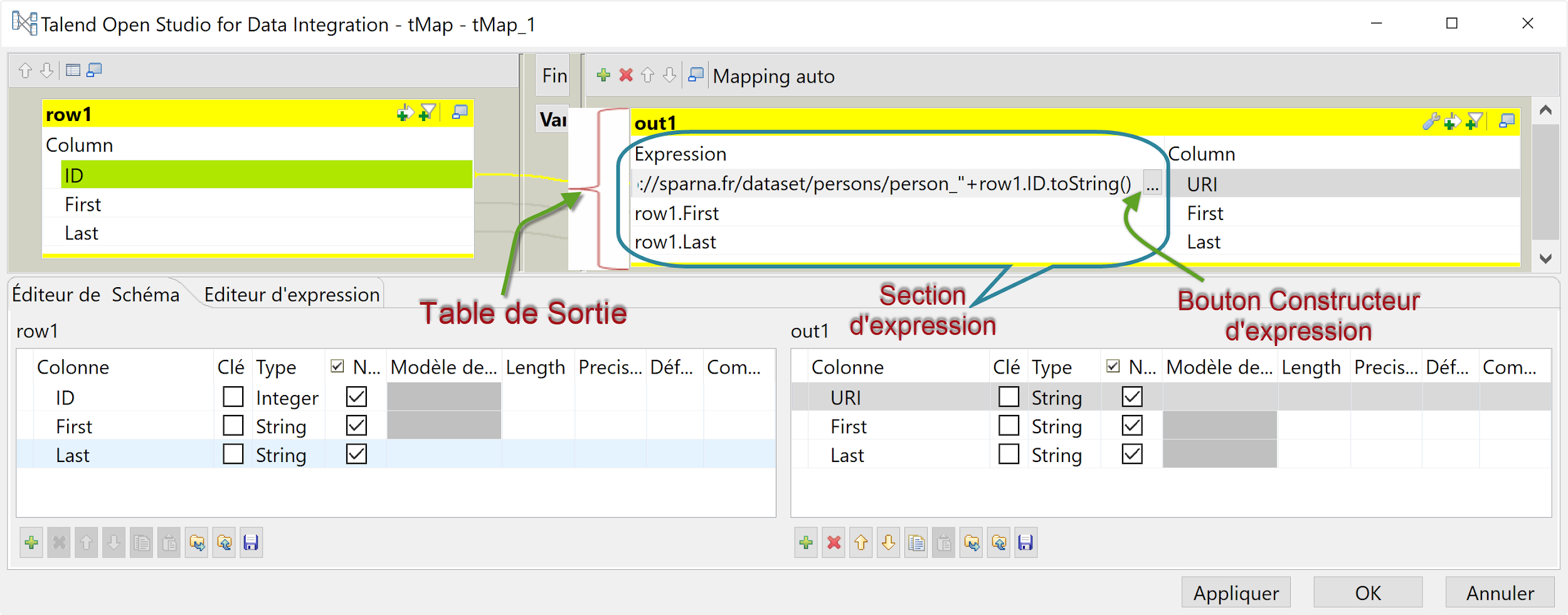
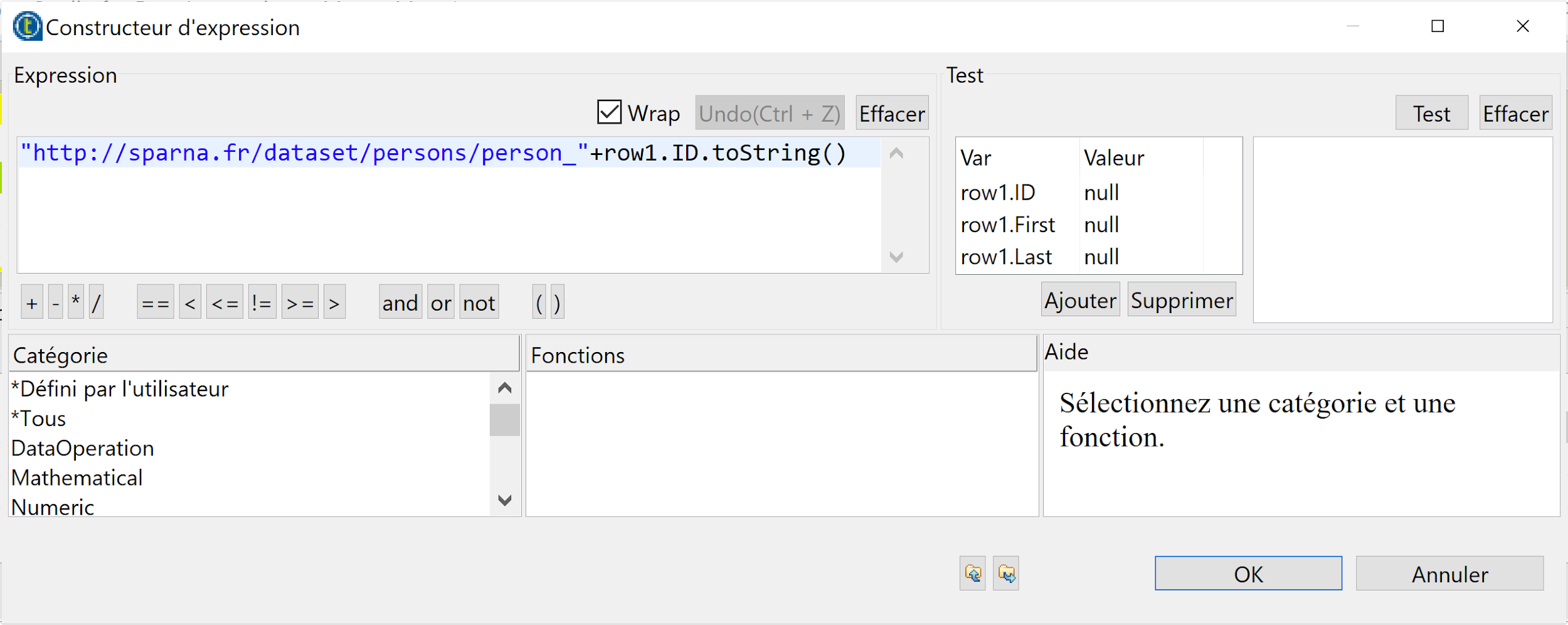
- Cliquez sur OKpour valider et revenir à l’espace de modélisation.
- Reliez le composant tMap_1 au composant tAdvancedFileOutputXML_1
Configurer la sortie RDF/XML
Une fois que toutes les informations nécessaires à la génération du RDF (en particulier les URIs) ont été produites, on peut mapper les différentes informations vers la structure d’un fichier RDF/XML de sortie.
- Nous allons définir l’arbre XML dans le composant tAdvancedFileOutputXML_1.
- Double-cliquez sur le composant tAdvancedFileOutputXML_1 pour ouvrir l’interface dédiée ou cliquez sur le bouton […] du champ Configure Xml Tree de l’onglet Basic settings dans la vue Component.
- Dans la section Linked Target (cible du lien), définissez la structure XML comme sortie.
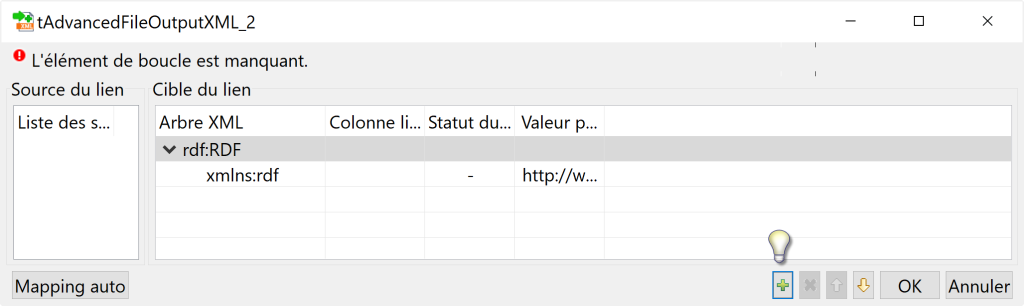
- Cliquez sur la ligne rootTag et renommer par rdf:RDF.

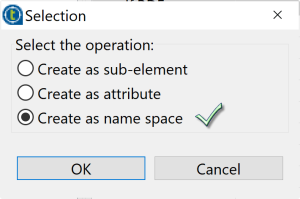
- Cliquez sur le bouton plus [+] et ajoutez une ligne de type namespace avec son prefix rdf et son namespace “http://www.w3.org/1999/02/22-rdf-syntax-ns#”.
- Etape 1:
- Étape 2: Choisissez l’option create as name space.
- Étape 3: Tapez le prefix et le Namespace.
- Etape 1:
- Cliquez sur la ligne rootTag et renommer par rdf:RDF.
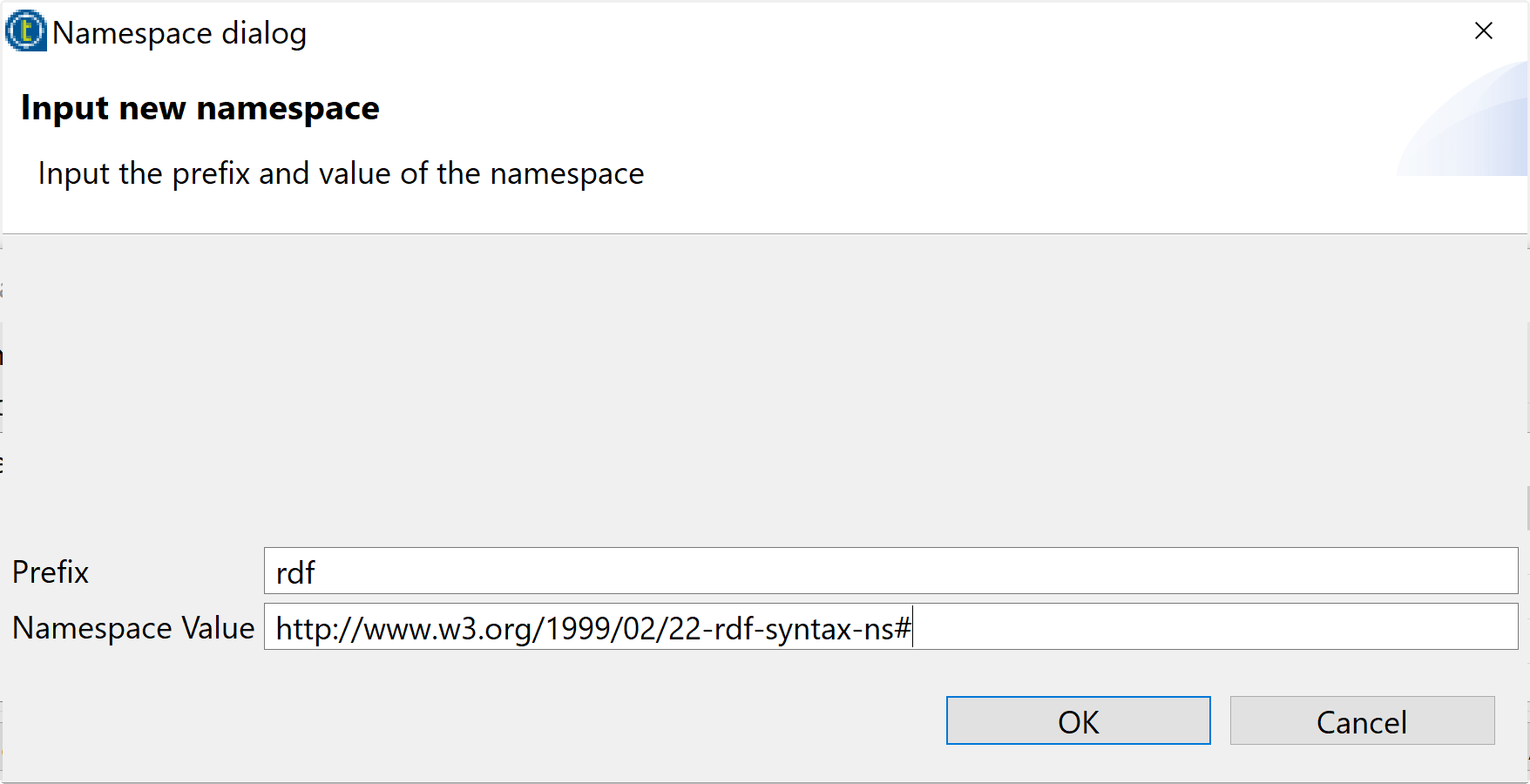
- Ajoutez autre namespace comment les pas précédents. et avec le prefix foaf et le namespace “http://xmlns.com/foaf/0.1/”.
- Choisissez la ligne racine (rdf:RDF) et Créer une sous élément qui doit s’appelle foaf:Person et cliquez sur le bouton OK.

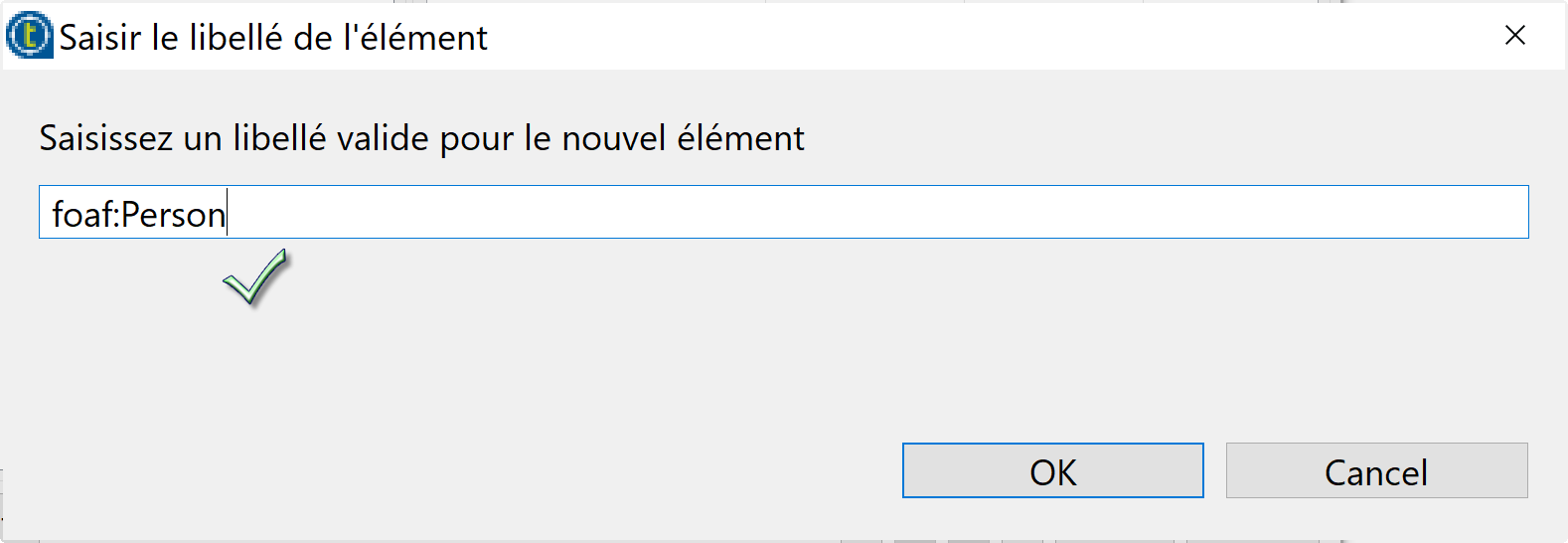
- Cliquez sur la ligne foaf:Person et créer un attribut rdf:about et cliquez sur le bouton OK.
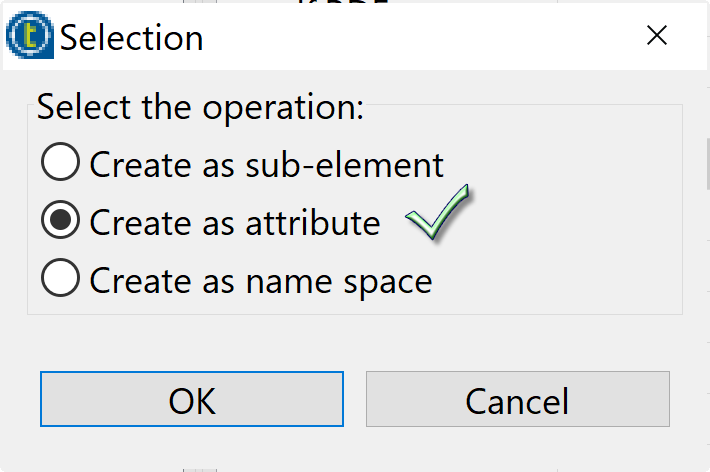

- Cliquez sur la ligne foaf:Person et ajoutez les sous éléments foaf:firstName et foaf:lastName.
- Pour connecter les sources avec la structure, glissez chaque champ source avec le champ cible. URI → @rdf:about et immédiatement s’afficher une fenêtre où nous devons choisir l’option Add linker to target node.
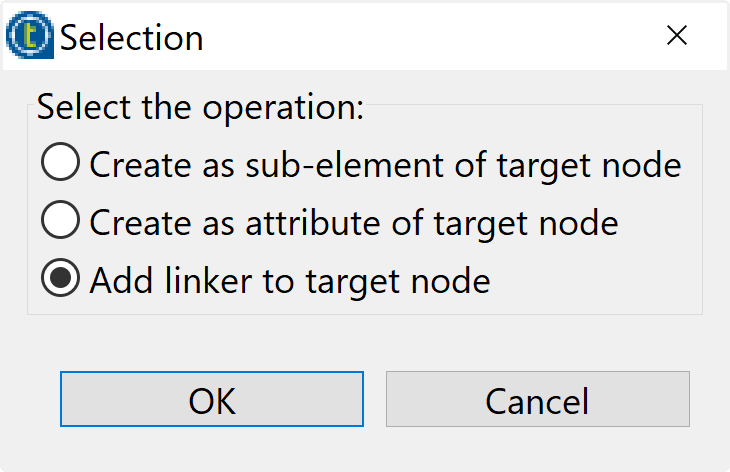
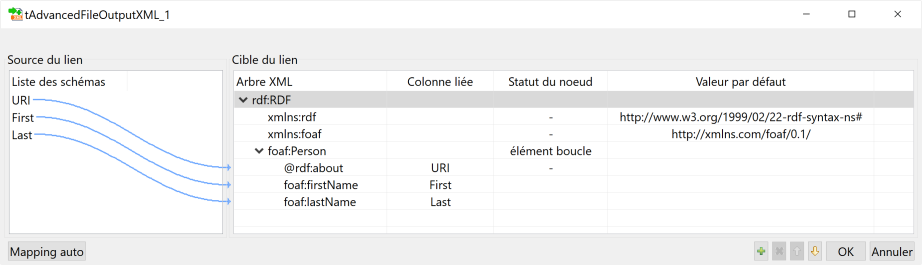
- Cliquez sur le bouton OK pour confirmer.
- Dans le Basic Settings du composant tAdvancedFileOutputXML_1, entrez le chemin de sauvegarde du fichier XML de sortie.
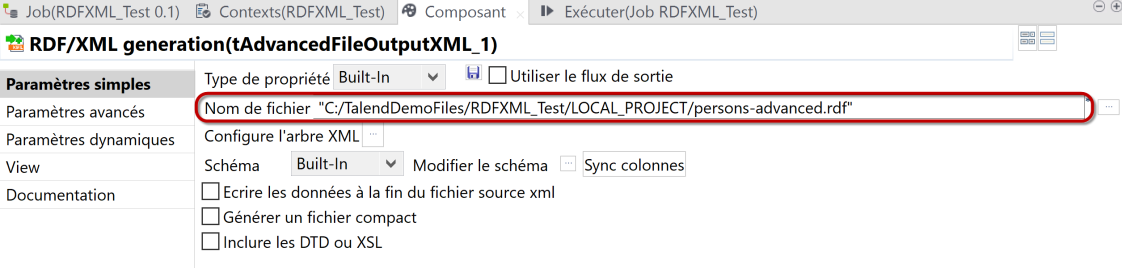
Lancer notre Job.
- Aller à la section Exécuter.
- Cliquez sur le bouton Exécuter.

- Le résultat final est la création du fichier RDF/XML, qui est stocké à l’endroit configuré.
Et voilà un magnifique fichier RDF/XML, produit à partir de CSV, en quelques clics et avec des composants graphiques ! Pas belle la vie ?
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/">
<foaf:Person rdf:about="http://sparna.fr/dataset/persons/person_1">
<foaf:firstName>Theodore</foaf:firstName>
<foaf:lastName>Roosevelt</foaf:lastName>
</foaf:Person>
<foaf:Person rdf:about="http://sparna.fr/dataset/persons/person_2">
<foaf:firstName>Ulysses</foaf:firstName>
<foaf:lastName>Clinton</foaf:lastName>
</foaf:Person>
<foaf:Person rdf:about="http://sparna.fr/dataset/persons/person_3">
<foaf:firstName>John</foaf:firstName>
<foaf:lastName>Truman</foaf:lastName>
</foaf:Person>
<foaf:Person rdf:about="http://sparna.fr/dataset/persons/person_4">
<foaf:firstName>Chester</foaf:firstName>
<foaf:lastName>Van Buren</foaf:lastName>
</foaf:Person>
<foaf:Person rdf:about="http://sparna.fr/dataset/persons/person_5">
<foaf:firstName>Rutherford</foaf:firstName>
<foaf:lastName>McKinley</foaf:lastName>
</foaf:Person>
</rdf:RDF>
Merci Thomas pour ce tuto, c’est pile ce que je cherchais